
对于艺术家和插图画家来说,这类绘图工具虽然省时省力,但如何保持自己的创作风格是一个大问题。
机器之心报道,编辑:杜伟、陈萍。
前段时间,来自慕尼黑大学和 Runway 的研究者,与Eleuther AI、LAION 等团队合作,共同开发了一种文本转图像模型 Stable Diffusion。这项研究入选CVPR 2022 Oral。
Stable Diffusion 可以在消费级 GPU 上的 10 GB VRAM 下运行,并在几秒钟内生成 512×512 像素的图像,无需预处理和后处理。
Stable Diffusion的生成效果是这样的。宇宙的演变:

生物的进化:

这成片质量妥妥达到了大片级别。试想一下,如果将Stable Diffusion的作图功能发展成为一种绘画工具,将其与Web UI相结合,会带来怎样的设计体验。现在,有这样一个项目,可以满足广大研究者的需求。
有了这个项目,没有系统学习UI知识的小伙伴,也可以上手操作。例如自己动手设计城堡,并且周围环境按自己喜好来设计:

在城堡外面安排一名侍卫,并让一位骑马的战士奔向城堡:

城堡上空的光线不好,想换种颜色,也以实现:

不过想要实现上述效果,还需要Gradio库,这是一个免费、开源的Python库,它允许用户为机器学习模型开发易于使用的可定制组件演示,还可以帮助用户构建一个可以互动的网络应用。
不过带有Gradio UI的原始脚本是由一位匿名用户编写的,现在该项目进行了一些修改:
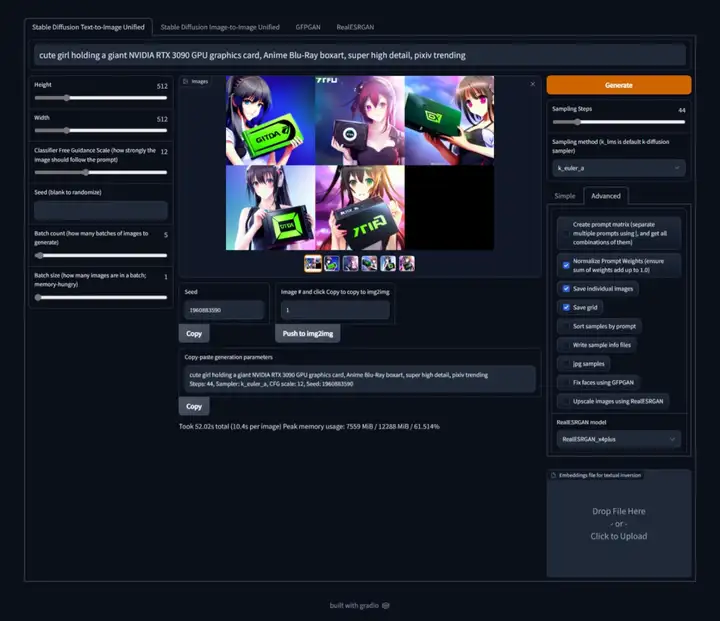
借助这一项目,用户不再需要手动输入参数,需要做的是编写提示并调整滑块就可以了,其强大的设计工具,还可用于重新生成要更改的图像的特定部分,并且生成的图像失真少、质量还高。
该库还内置了GFPGAN选项,不到半秒就能修复失真人脸;此外还内置了RealESRGAN选项,用来提高图像的分辨率。
网友:文本转图像模型有利有弊
对于Stable Diffusion的这一应用,众多网友表示「赞极了」。

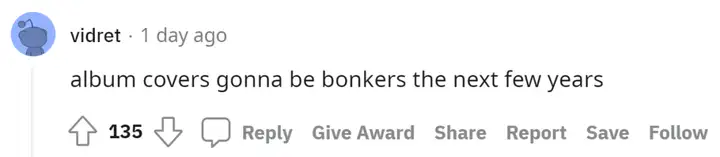
对于它的应用前景,更有人预测称,「未来几年用它做专辑封面将会变得更加疯狂。」
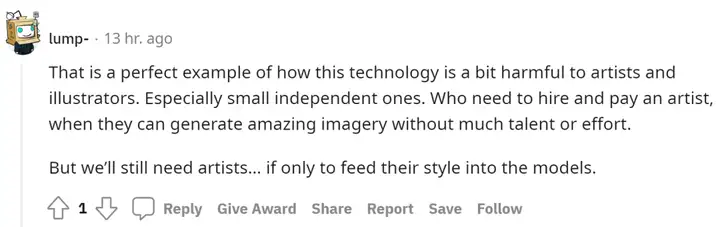
不过也有持相反意见的,认为「这是该技术对艺术家和插图画家有害的典型例子,他们不用付出太多天赋和努力就能生成不可思议的艺术图像。不过未来仍需要艺术家,只要他们将自己的风格融入到这些模型中。」
还有些网友认为,文本转图像有点像语言翻译领域正在经历的事情。借助机器学习模型生成的译文质量不一,然后译者对译文进行润色编辑。而由于生成的图像具有各种各样的伪影,艺术家们可能要做更多的修饰工作。



















暂无评论内容