

Midjourney工具获奖图片
好吗,人工智能虽然已经涉及到人类的方方面面,但没有想到,AI 还能抢艺术家的饭碗,这不,一位小哥使用AI工具生成的艺术照片竟然获奖了,而且还是一等奖,且最近刚刚火起来的stable diffusion 更是让艺术家与AI发生了争执,到底AI是否抢了艺术家的饭碗,还是AI生成的图片有没有艺术,我们不做讨论,本期我们就带领大家试玩一下stable diffusion模型。
——1——
什么是stable diffusion模型
stable diffusion模型是Stability AI开源的一个text-to-image的扩散模型,其模型在速度与质量上面有了质的突破,玩家们可以在自己消费级GPU上面来运行此模型,本模型基于CompVis 和 Runway 团队的Latent Diffusion Models,
https://github.com/CompVis/stable-diffusionhttps://github.com/CompVis/latent-diffusion
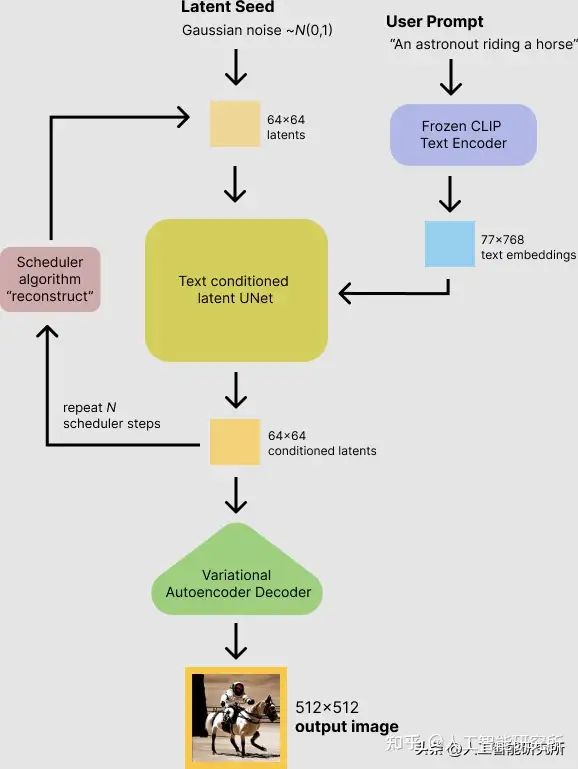
stable diffusion模型核心数据集在 LAION-Aesthetics 上进行了训练,该模型在Stability AI 4,000 个 A100 Ezra-1 AI 超集群上进行了训练,能够在消费级10 GB VRAM GPU 上运行,可在几秒钟内生成 512×512 像素的图像。
潜在扩散模型可以通过在较低维潜在空间上应用扩散过程来降低内存和计算复杂性,而不是使用实际的像素空间。这是标准扩散和潜在扩散模型之间的主要区别:在潜在扩散中,模型被训练以生成图像的潜在(压缩)表示。
潜在扩散模型主要有
An autoencoder (VAE).
A U-Net.
A text-encoder, e.g. CLIPs Text Encoder.1.自动编码器(VAE)
VAE 模型有两个部分,编码器和解码器。编码器用于将图像转换为低维潜在表示图形,作为 U-Net 模型的输入。相反,解码器将潜在表示转换回原图像。
在潜在扩散模型训练期间,编码器用于获取图像的潜在表示以进行前向扩散过程,该过程在每个步骤中应用越来越多的噪声。在推理过程中,反向扩散过程产生的去噪值使用 VAE 解码器转换回图像。
2. U-Net
U-Net 有一个编码器部分和一个解码器部分,都由 ResNet 块组成。编码器将图像压缩为较低分辨率的图像表示,而解码器将较低分辨率的图像解码回原始的较高分辨率的图像表示,该表示应该是噪声较小的。
为了防止 U-Net 在下采样时丢失重要信息,通常在编码器的下采样 ResNet 和解码器的上采样 ResNet 之间添加快捷连接。此外,稳定地扩散 U-Net 能够通过交叉注意力层在文本嵌入上调节其输出。交叉注意力层被添加到 U-Net 的编码器和解码器部分,通常在 ResNet 块之间。
3. 文本编码器
文本编码器负责转换输入,例如“一个骑着马的宇航员”进入一个 U-Net 可以理解的嵌入空间。它通常是一个简单的基于转换器的编码器,将输入标记序列映射到潜在文本嵌入序列。类似与transformer模型的word-embedding

受 Imagen 的启发,Stable Diffusion 在训练期间不训练文本编码器,而是使用 CLIP 已经训练好的文本编码器 CLIPTextModel。
由于潜在扩散模型的 U-Net 在低维空间上运行,与像素空间扩散模型相比,它大大降低了内存和计算需求。例如,Stable Diffusion 中使用的自动编码器的缩减因子为 8。这意味着形状为 (3, 512, 512) 的图像在潜在空间中变为 (3, 64, 64),需要 8 × 8 = 64 更少的内存。

——2——
代码实现Stable Diffusion
Stable Diffusion模型的预训练已经达到4G之多,要是运行在自己的本地电脑,需要耗费很大的电脑资源,好在Stable Diffusion已经加入Hugging Face套餐,我们可以使用Hugging Face来运行此模型,当然这里需要你有一个Hugging Face的账号,并在自己的账号中获取了运行模型的tokens值
https://huggingface.co/settings/tokens然后打开Google colab,毕竟模型太大,我们使用Google colab的免费GPU资源来运行代码。进入自己的Google colab后,需要设置一下运行环境为GPU,菜单栏>>代码执行程序>>更改运行时类型,选择GPU,保存即可,这样,我们的代码会运行在GPU上面
!pip install diffusers==0.3.0
!pip install transformers scipy ftfy
!pip install “ipywidgets>=7,<8”首先,我们需要导入第三方库来运行本次代码
然后我们需要复制Hugging Face账号下的tokens,运行下面代码时,会提示要输入token值,到自己的账号下面复制即可
from google.colab import output
output.enable_custom_widget_manager()
from huggingface_hub import notebook_login
notebook_login()以上代码运行成功后,我们便可以加载预训练模型了,这里加载的是stable-diffusion-v1-4,1-4版本是stable-diffusion目前最新的版本
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(“CompVis/stable-diffusion-v1-4″, revision=”fp16”, torch_dtype=torch.float16, use_auth_token=True)运行代码后,模型会自动下载stable-diffusion的预训练模型
加载完模型后,我们便可以输入一句英文的句子来生成相应的图片了
pipe = pipe.to(“cuda”)
from torch import autocast
prompt = “a photograph of iron man and technology computer table”
with autocast(“cuda”):
image = pipe(prompt).images[0]
image.save(f”astronaut_rides_horse.png”)
image运行代码后,确实运行速度很快,在10s左右的时间,便可以生成了我们的图片

钢铁侠坐在科幻电脑桌面前

一个十分科幻的电脑桌面

一个十分科幻的古堡
当然由于我们的英文水平,有可能模型生成的不是我们需要的图片,这里可以优化自己的句子来生成我们想要的图片,当然以上代码生成的图片是标准的512*512尺寸的,你也可以改变里面的参数来生成较大尺寸的图片
prompt = ” a photograph of iron man and technology computer table “
with autocast(“cuda”):
image = pipe(prompt, height=512, width=768).images[0]
image
也可以使用如下代码来生成多张图片,进行比较,挑选自己想要的照片,因为模型每次生成的图片并不是一样的,有可能同样的句子,生成的图片也不完全相同
num_cols = 3
num_rows = 4
prompt = [“a photograph of iron man and technology computer table “] * num_cols
all_images = []
for i in range(num_rows):
with autocast(“cuda”):
images = pipe(prompt).images
all_images.extend(images)
grid = image_grid(all_images, rows=num_rows, cols=num_cols)
grid
——3——
paddle代码实现Stable Diffusion
当然,除了Hugging Face可以使用Stable Diffusion模型外,百度paddlepaddle 也可以来使用此模型,在Google colab上面新建一个工程,安装paddlepaddle

!pip install –upgrade paddlepaddle
!pip install –upgrade paddlehub然后在代码中添加如下代码,直接运行即可

import paddlehub as hub
module = hub.Module(name=”stable_diffusion”)
text_prompts = [“in the morning light,Overlooking TOKYO city by greg rutkowski and thomas kinkade,Trending on artstation.”]
当然我们很多小伙伴的英文并不是很好的情况下,可以使用paddlepaddle 下的中文模型

import paddlehub as hub
module = hub.Module(name=”ernie_vilg”)
text_prompts = [“日落时的枫树,秋天风格”]
images = module.generate_image(text_prompts=text_prompts, style=油画, output_dir=./ernie_vilg_out/)

当然还支持disco_diffusion_clip_vitb32
import paddlehub as hub
module = hub.Module(name=”disco_diffusion_clip_vitb32″)
text_prompts = [“A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.”]
# 生成图像, 默认会在
disco_diffusion_clip_vitb32_out目录保存图像
# 返回的da是一个DocumentArray对象,保存了所有的结果,包括最终结果和迭代过程的中间结果
# 可以通过操作DocumentArray对象对生成的图像做后处理,保存或者分析
da = module.generate_image(text_prompts=text_prompts, output_dir=./disco_diffusion_clip_vitb32_out/)
# 手动将最终生成的图像保存到指定路径
da[0].save_uri_to_file(disco_diffusion_clip_vitb32_out-result.png)
# 展示所有的中间结果
da[0].chunks.plot_image_sprites(skip_empty=True, show_index=True, keep_aspect_ratio=True)
# 将整个生成过程保存为一个动态图gif
da[0].chunks.save_gif(disco_diffusion_clip_vitb32_out-result.gif)
stable-diffusion也支持在线演示,可以访问如下

VX搜索小程序:AI人工智能工具,体验不一样的AI工具





















暂无评论内容