
在正式教程之前、聊聊dreambooth的发展、帮大家理清一下思绪
dreambooth发展史
画了张图帮助大家理解dreambooth的发展史
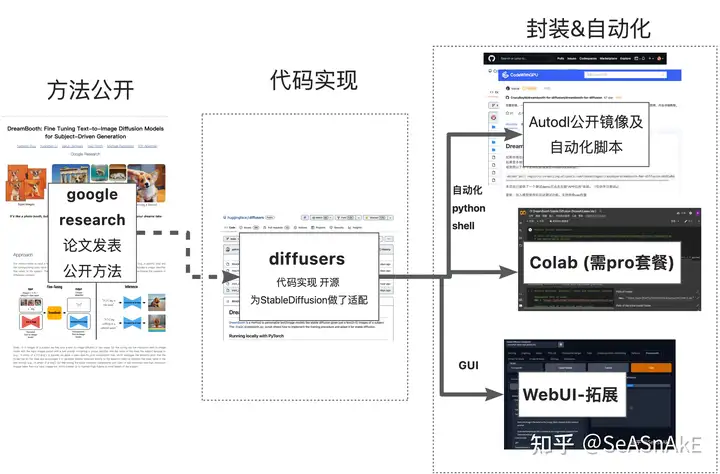
综合搭建成本、以及训练质量和使用者心智负担、目前调研下来推荐、基于autodl上提供的公开镜像来创建实例进行训练 (https://github.com/CrazyBoyM/dreambooth-for-diffusion)
训练全流程教程
在本次教程中 Webui 不再是主战场 主角是 diffusers, 我们要通过调整运行时的命令行参数 或是直接在python和shell脚本修改变量来实现训练参数的调整、直接在服务器上修改相应的shell和python脚本执行训练(没有Web客户端gui)
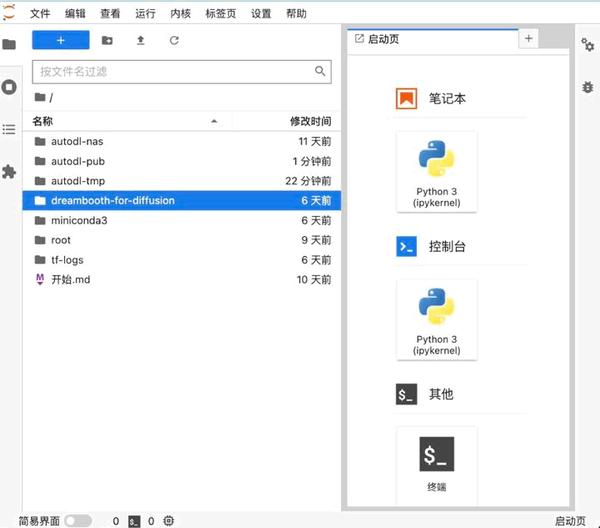
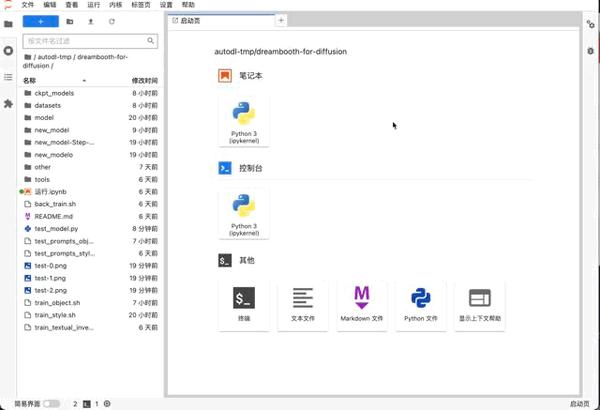
基建准备
autodl(没有账号的先去注册一个 新用户注册会送十块钱 足够大家训练几次Dreambooth 了AutoDL-品质GPU租用平台-租GPU就上AutoDL) 点击镜像链接 CodeWithGPU | 能复现才是好算法拉镜像(镜像预装了所有训练所需依赖 并且内置了stable- diffusion 1.5 和 novel ai 模型 nd 使我们只需专注于训练上) 创实例 (最好是3090或者A5000) 创建过程大概几分钟左右
模型转换
挑选要训练的ckpt模型文件 转成diffusers权重(两者格式不同、ckpt相当于把好几个文件权重打包)(镜像内置了stable- diffusion 1.5模型(三次元) 和 nai 模型(二次元) )终端输入以下命令 进行转换
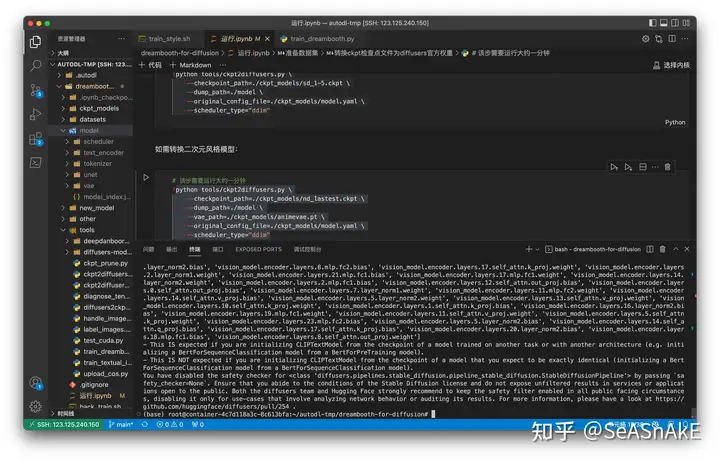
数据集准备
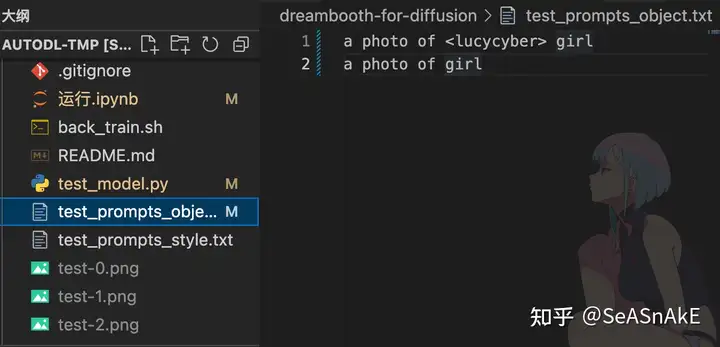
./datasets/test是原始图片数据文件夹,请上传你的图片数据并进行更换数据集展示(5张) 裁剪为512×512 切图网站: BIRME – Resize multiple images (Online & Free)
设置训练参数
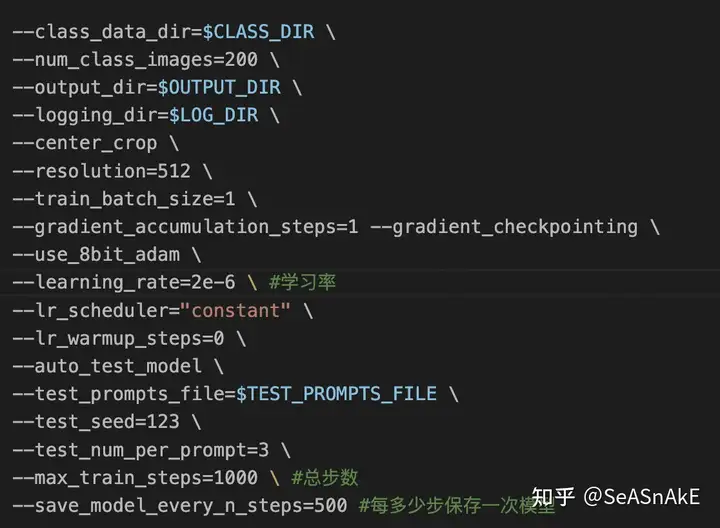
调整参数 train_object.sh 中作相应修改(见下图中#注释 没有注释的参数字段默认帮你配置了常用的参数 不用改也能跑)class nameinstant_prompt学习率 (默认)步数 (默认)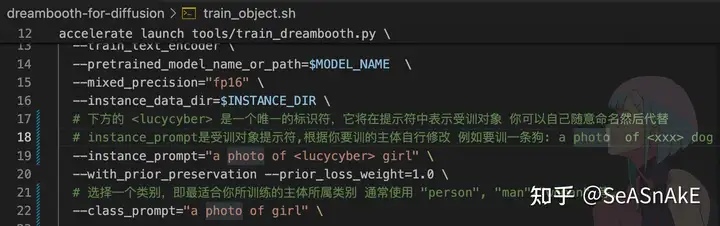
开始训练
终端中输入 sh train_object.sh 回车开始训练(每次用dreambooth训练一个主体时 会先根据上面设置的class_prompt值生成先验知识图库(黑话:古法炼治)所以前十分钟在生成同类别伪图 之后才开始正式训练)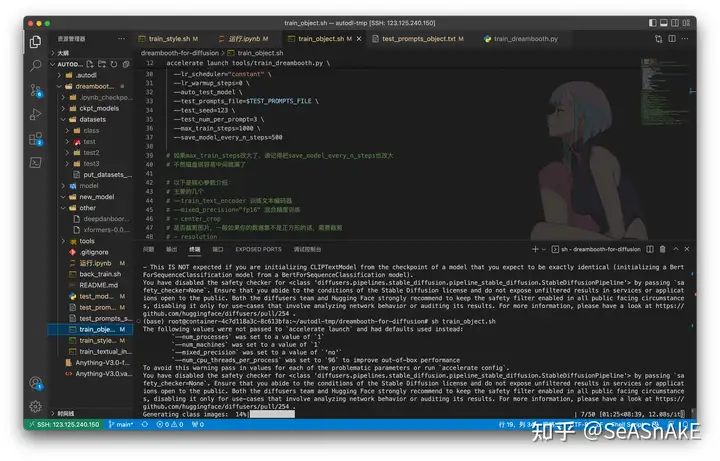
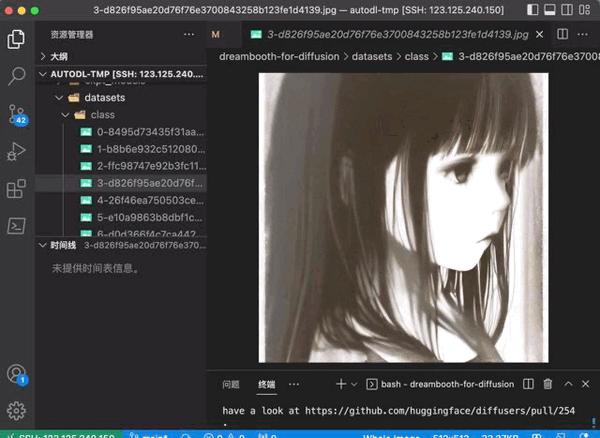
测试效果
查看 训练时生成的 测试图

测试结果图镜像 test_model.py 提供简单的 txt2img功能打开dreambooth-for-diffusion/test_model.py文件修改其中的model_path和prompt,然后执行以下测试
会生成一张图片 在左侧test-1、2、3.png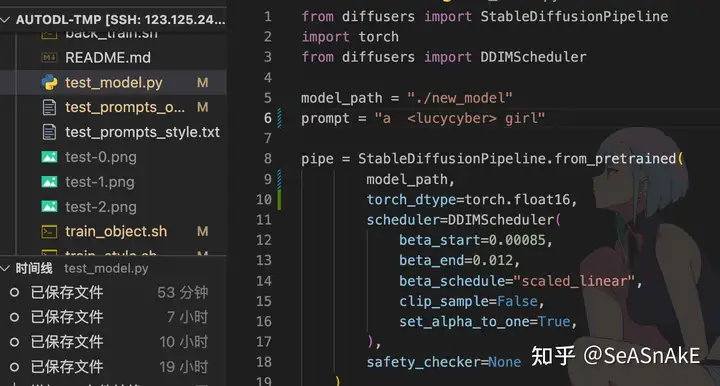
(如何以某个节点开始继续训练)
MODEL_NAME值修改为你准备继续训的模型节点路径
修改 train_object.sh 要训练与上次相同的特定物体/人物,所以之前生成的先验图库继续沿用无需删除
如下图注释掉rm -rf $CLASS_DIR/*这一行(前面加#即可)
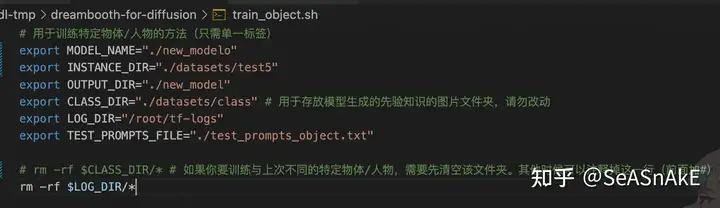
自行根据镜像里的说明文档调整其他参数
终端中输入 sh train_object.sh 回车开始继续训练
转换diffusers官方权重为ckpt检查点文件
终端中输入 python tools/diffusers2ckpt.py ./new_model(换成你挑选的模型文件夹 例如new_model-Step-xxx) ./ckpt_models/newModel.ckpt 回车 上述代码添加–half 保存float16半精度,权重文件大小会减半(约2g),效果基本一致至此训练顺利完成、开始传送装载
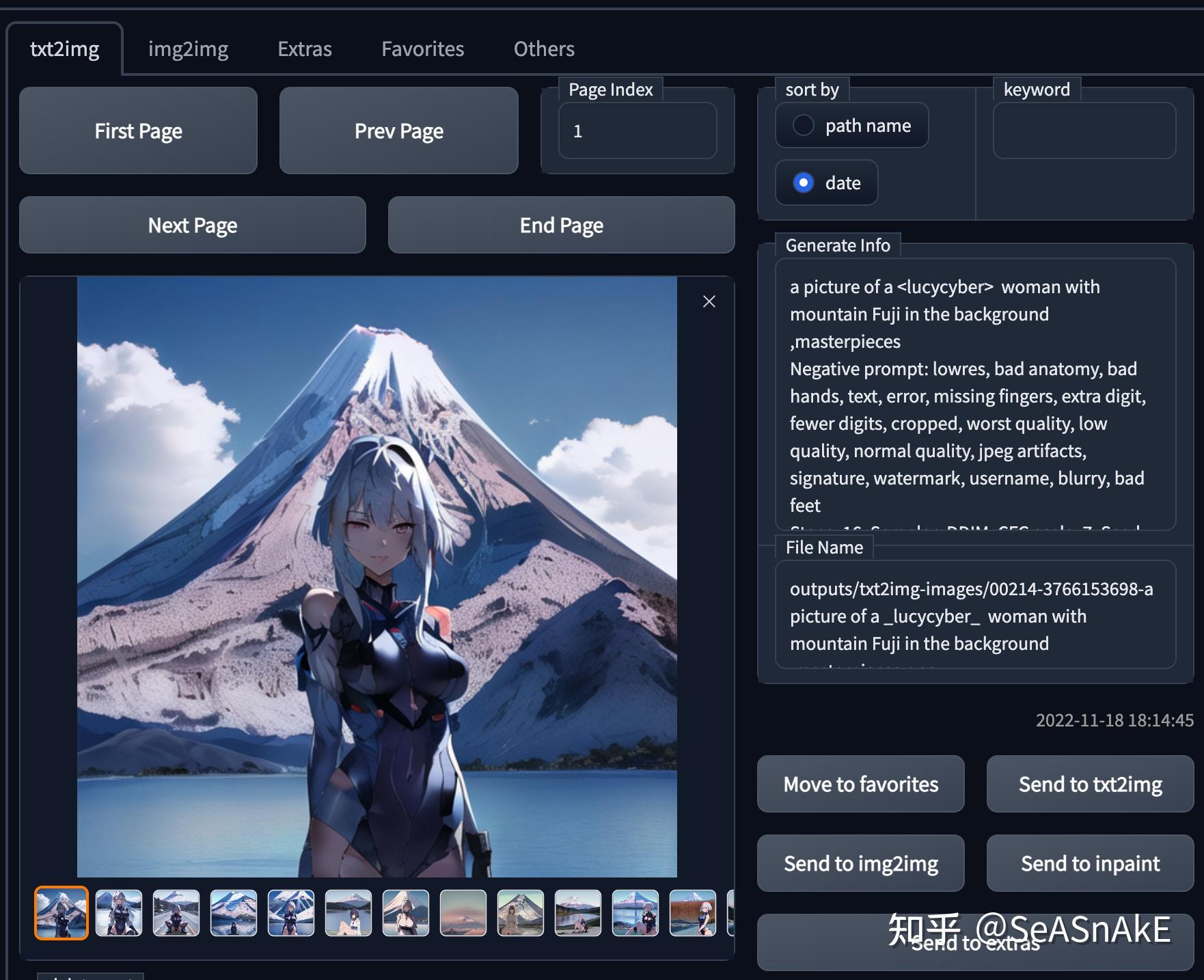
把 DreamBooth 训练出的 .ckpt 文件传到 webui 的models\Stable-diffusion目录里,在 webui 的左上角切换到即可使用。等待镜像加载完成,就可以通过在prompt里输入你之前指定的标志符(例如本教程中使用的为 <lucycyber> )来让ai在生成图像中加入你之前训练的主体
效果展示
txt2img

融入景观

风格迁移

img2img (可搭配其他模型 和 hypernetwork 进一步调整图像质量和细节)
此处以封面出图过程为例 下面是dreambooth训练模型直出原图、然后进行一系列调整

inpaint + loopback 修改细节 (不知道为啥训的衣服老是破破烂烂的…)

搭配其他模型 和 hypernetwork 调整

成品

参考链接
dreambooth论文:https://dreambooth.github.io/
diffusers dreambooth文档:https://github.com/huggingface/diffusers/tree/main/examples/dreambooth
镜像作者文档:https://github.com/CrazyBoyM/dreambooth-for-diffusion
ai-draw文档:https://stable-diffusion-book.vercel.app/train/DreamBooth/
相关文章



















暂无评论内容