
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
Stable Diffusion插件、“AI绘画细节控制大师”ControlNet迎来重磅更新:
只需使用文本提示词,就能在保持图像主体特征的前提下,任意修改图像细节。
比如给美女从头发到衣服都换身造型,表情更亲和一点:

抑或是让模特从甜美邻家女孩切换到高冷御姐,身体和头部的朝向、背景都换个花样儿:

——不管细节怎么修改,原图的“灵魂”都还在。
除了这种风格,动漫类型的它也能驾驭得恰到好处:

来自推特的AI设计博主@sundyme就称:
效果比想象得要好!
只需要一张参考图就能完成以上转变,部分图片几乎可以达到定制大模型的效果了。
咳咳,各位AI绘画圈的朋友们,打起精神来,又有好玩的了。
(ps. 第一三张效果图来自油管博主@Olivio Sarikas,第二张来自推特博主@sundyme)
ControlNet上新:保留原图画风的修图功能
以上更新内容,其实指的是一个叫做“reference-only”的预处理器。
它不需要任何控制模型,直接使用参考图片就能引导扩散。
作者介绍,这个功能其实类似于“inpaint”功能,但不会让图像崩坏。
(Inpaint是Stable Diffusion web UI中的一个局部重绘功能,可以将不满意、也就是被手工遮罩的地方进行重新绘制。)
一些资深玩家可能都知道一个trick,就是用inpaint来进行图像扩散。
比如你有一张512×512的狗的图像,然后想用同一只狗生成另一张512×512的图像。
这时你就可以将512×512的狗图像和512×512的空白图像连接到一张1024×512的图像中,然后使用inpaint功能,mask掉空白的512×512部分,漫射出具有相似外观的狗的形象。
在这个过程中,由于图像只是简单粗暴的进行拼接,加上还会出现失真现象,所以效果一般都不尽如人意。
有了“reference-only”就不一样了:
它可以将SD(即“Stable Diffusion”)的注意力层直接链接到任何独立的图像,方便SD直接读取这些图像作为参考。
也就是说,现在你想要在保持原图风格的前提下进行修改,使用提示词直接在原图上就能操作。
如官方示例图将一只静立的小狗改成奔跑动作:
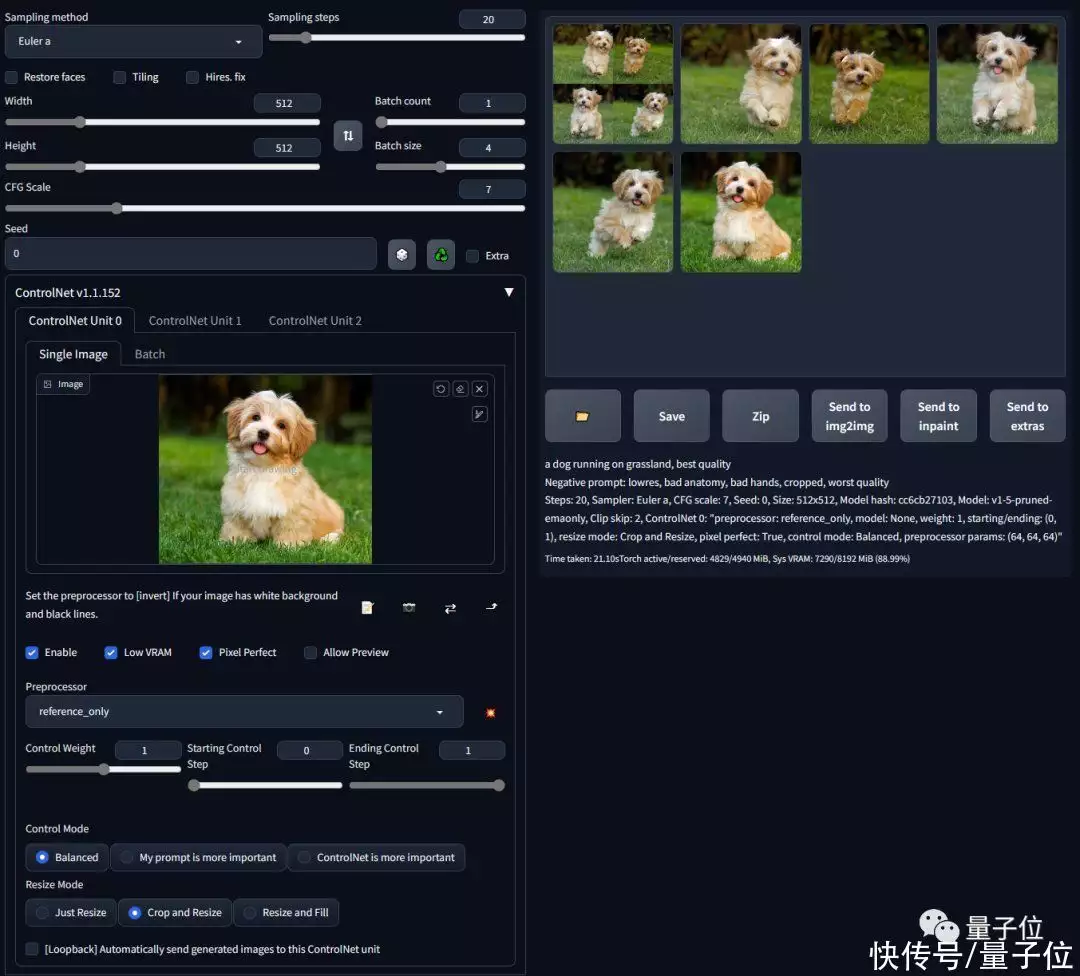
你只需要将你的ControlNet升级到1.1.153版本以上,然后选择“reference-only”作为预处理器,上传狗的图片,输入提示词“a dog running on grassland, best quality……”,SD就只会用你的这张图作为参考进行修改了。
网友:ControlNet迄今最好的一个功能
“reference-only”功能一出,有不少网友就上手体验了。
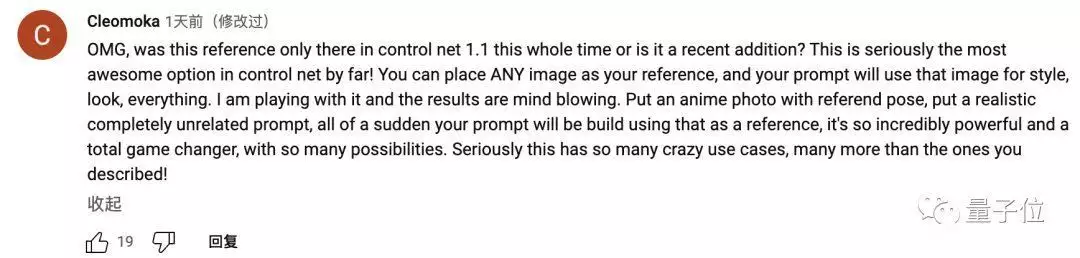
有人称这是ControlNet迄今为止最棒的一个功能:
传一张带有人物姿势的动漫图片,再写一句看上去跟原图完全无关的提示。突然之间,你想要的效果就在原图的基础上跑出来了。真的很强,甚至说是达到了改变游戏规则的程度。
还有人称:
是时候把以前丢弃的废图都捡回来重新修复一下了。

当然,认为它也不是那么完美也有(比如开头第一张效果图里美女的耳环不对,二张图里头发也都是残缺的),但网友还是表示“总归方向是对了”。

以下是三位推特博主尝试的效果,主要都是动漫风,一起欣赏一下:

△来自@新宮ラリのAIイラストニュ

△来自@br_d,左一为原图

△来自@br_d,上一为原图

△来自@uoyuki667,左一为原图
有没有戳中你的心巴?
参考链接:
[1]https://github.com/Mikubill/sd-webui-controlnet/discussions/1236[2]https://twitter.com/sundyme/status/1657605321052012545[3]https://twitter.com/uoyuki667/status/1657748719155167233[4]https://twitter.com/br_d/status/1657926233068556289[5]https://twitter.com/aiilustnews/status/1657941855773003776— 完 —
量子位 QbitAI · 头条号签约


















暂无评论内容