序
随着越来越多的人追上”AI绘图”这一热潮,Stable Diffusion 的受欢迎程度继续爆炸式增长。
作为模型公开且效果极佳的扩散模型Stable Diffusion是CompVis研究团队上个月(8月底)发布的。该模型使用 LAION 5B 数据集的子集进行训练,包括用于初始训练的高分辨率子集和用于后续各种开发者提升”美学”孕育出来的的各种针对性模型。
我们可以通过自己下载,获得一个极其强大的模型,该模型能够模拟和重建几乎任何可以以视觉形式想象的概念,而无需文本提示输入之外的任何指导。关于本地部署可以参考之前我发的文章:
在本文中,我将展示一下 Stable Diffusion Web UI 的应用效果,这个模块主要是基于stable diffusion的基础应用,利用gradio模块搭建出交互程序,但其中很多方法比原始模型提供了更多接口。安装使用也更加方便,使用户可以在低代码 GUI 中立即访问 Stable Diffusion。
可以说,其中最受欢迎和经常更新的是 AUTOMATIC111 的 Stable Diffusion Web UI 搭建的工作。除了 txt2img、img2img等 Stable Diffusion 的基本功能外,Web UI 还包含许多模型融合改进、图片质量修复等许多附加升级——所有这些都可以通过易于使用的方式访问Web 应用程序图形用户界面。
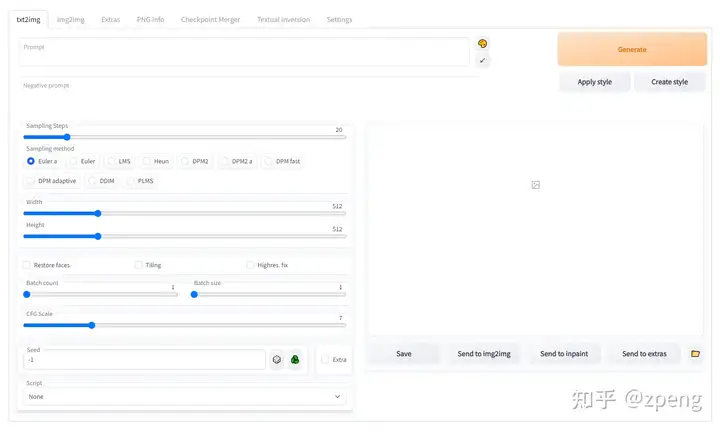
搭建完成,我们可以通过浏览器访问到下面的界面:
运行后的效果图:
通过调节不同参数可以生成不同效果,我这里根据自己的使用理解进行一些说明,希望对用户有帮助。
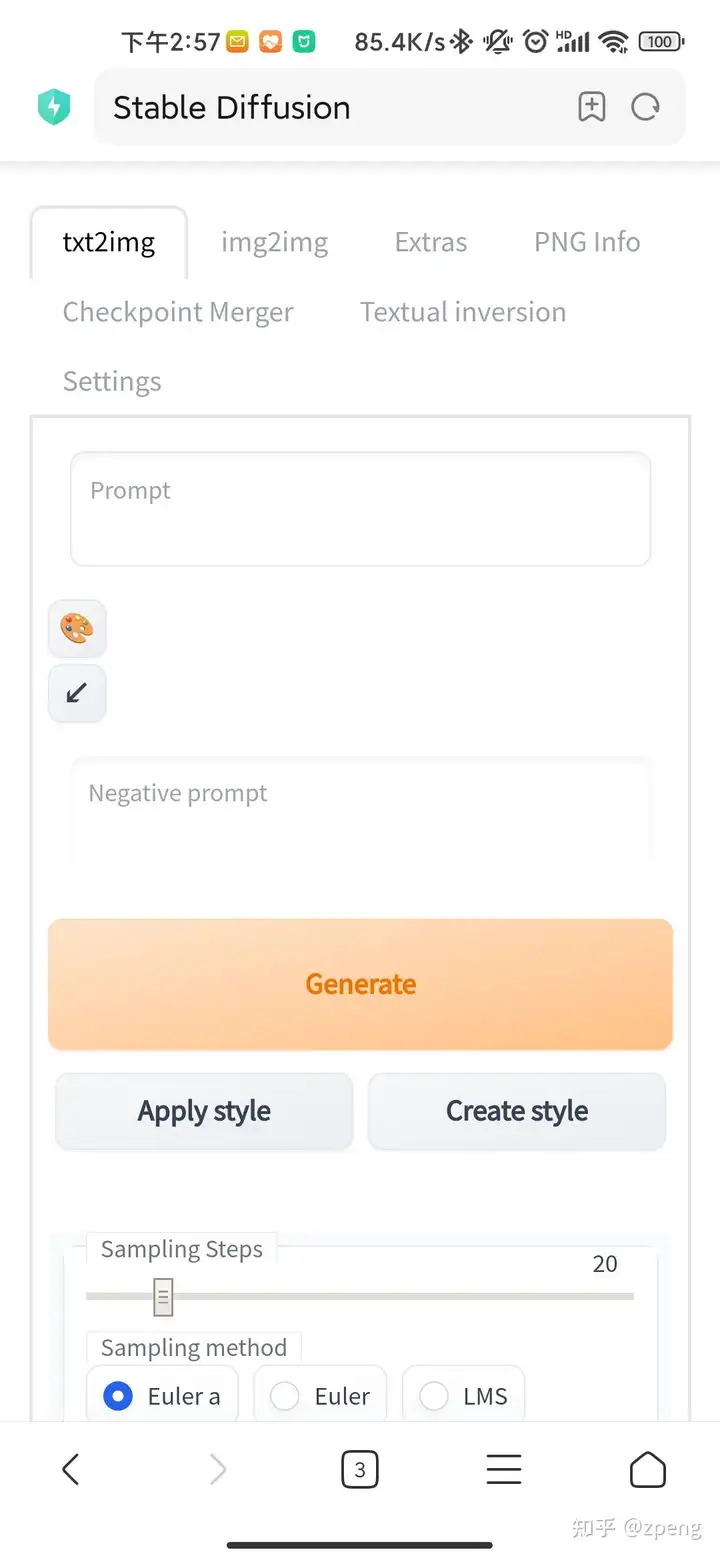
同时在手机上也可以访问及使用,但测试时候使用手机默认浏览器没问题,用夸克会报错。
安装
基于上次的经验,这里要说明:以下设置还是需要一定计算机功底的,如果配置环境、安装包等问题默认大家都是ok的。计算资源需求很大,很有可能会因为显存不足报错;
从github上下载最新版本的stable-diffusion-webui, 链接:
安装手册有Windows、Linux、MacOS,我是用的是Linux版本,其他没有测试;
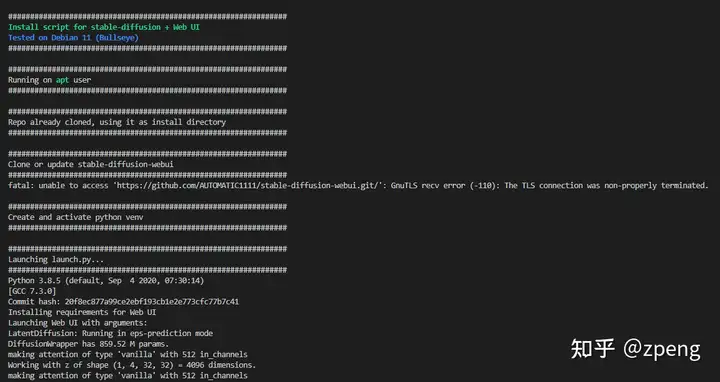
我是基于之前配置好的stable-diffusion的环境进行配置的,并且环境里的python、wget和git都是配置好之后就很简单,直接使用目录下的shell脚本,会对于环境、安装包、模型下载自动完成。
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
它可以自己下载和配置环境,我这里基本就是将模型文件进行了链接,还有网络端口进行了修改。启动时间还是比较漫长:
如果默认启动模型使用的是127.0.0.1启动,如果想让其他设备访问webui.py的模块中修改server_name 参数he server_port参数:
demo.launch(
share=cmd_opts.share,
server_name=”192.168.*.*” ,#if cmd_opts.listen else None,
server_port=cmd_opts.port,
debug=cmd_opts.gradio_debug,
auth=[tuple(cred.split(:)) for cred in cmd_opts.gradio_auth.strip(“).split(,)] if cmd_opts.gradio_auth else None,
inbrowser=cmd_opts.autolaunch,
prevent_thread_lock=True
)
相关参数还可以通过modules/shared.py进行修改:
parser.add_argument(“–config”, type=str, default=os.path.join(sd_path, “configs/stable-diffusion/v1-inference.yaml”), help=”path to config which constructs model”,)
parser.add_argument(“–ckpt”, type=str, default=sd_model_file, help=”path to checkpoint of stable diffusion model; if specified, this checkpoint will be added to the list of checkpoints and loaded”,)
parser.add_argument(“–ckpt-dir”, type=str, default=None, help=”Path to directory with stable diffusion checkpoints”)
parser.add_argument(“–gfpgan-dir”, type=str, help=”GFPGAN directory”, default=(./src/gfpgan if os.path.exists(./src/gfpgan) else ./GFPGAN))
parser.add_argument(“–gfpgan-model”, type=str, help=”GFPGAN model file name”, default=None)
parser.add_argument(“–no-half”, action=store_true, help=”do not switch the model to 16-bit floats”)
parser.add_argument(“–no-progressbar-hiding”, action=store_true, help=”do not hide progressbar in gradio UI (we hide it because it slows down ML if you have hardware acceleration in browser)”)
parser.add_argument(“–max-batch-count”, type=int, default=16, help=”maximum batch count value for the UI”)
parser.add_argument(“–embeddings-dir”, type=str, default=os.path.join(script_path, embeddings), help=”embeddings directory for textual inversion (default: embeddings)”)
parser.add_argument(“–allow-code”, action=store_true, help=”allow custom script execution from webui”)
parser.add_argument(“–medvram”, action=store_true, help=”enable stable diffusion model optimizations for sacrificing a little speed for low VRM usage”)
parser.add_argument(“–lowvram”, action=store_true, help=”enable stable diffusion model optimizations for sacrificing a lot of speed for very low VRM usage”)
parser.add_argument(“–always-batch-cond-uncond”, action=store_true, help=”disables cond/uncond batching that is enabled to save memory with –medvram or –lowvram”)
parser.add_argument(“–unload-gfpgan”, action=store_true, help=”does not do anything.”)
parser.add_argument(“–precision”, type=str, help=”evaluate at this precision”, choices=[“full”, “autocast”], default=”autocast”)
parser.add_argument(“–share”, action=store_true, help=”use share=True for gradio and make the UI accessible through their site (doesnt work for me but you might have better luck)”)
parser.add_argument(“–codeformer-models-path”, type=str, help=”Path to directory with codeformer model file(s).”, default=os.path.join(model_path, Codeformer))
parser.add_argument(“–gfpgan-models-path”, type=str, help=”Path to directory with GFPGAN model file(s).”, default=os.path.join(model_path, GFPGAN))
parser.add_argument(“–esrgan-models-path”, type=str, help=”Path to directory with ESRGAN model file(s).”, default=os.path.join(model_path, ESRGAN))
parser.add_argument(“–bsrgan-models-path”, type=str, help=”Path to directory with BSRGAN model file(s).”, default=os.path.join(model_path, BSRGAN))
parser.add_argument(“–realesrgan-models-path”, type=str, help=”Path to directory with RealESRGAN model file(s).”, default=os.path.join(model_path, RealESRGAN))
parser.add_argument(“–scunet-models-path”, type=str, help=”Path to directory with ScuNET model file(s).”, default=os.path.join(model_path, ScuNET))
parser.add_argument(“–swinir-models-path”, type=str, help=”Path to directory with SwinIR model file(s).”, default=os.path.join(model_path, SwinIR))
parser.add_argument(“–ldsr-models-path”, type=str, help=”Path to directory with LDSR model file(s).”, default=os.path.join(model_path, LDSR))
parser.add_argument(“–opt-split-attention”, action=store_true, help=”force-enables cross-attention layer optimization. By default, its on for torch.cuda and off for other torch devices.”)
parser.add_argument(“–disable-opt-split-attention”, action=store_true, help=”force-disables cross-attention layer optimization”)
parser.add_argument(“–opt-split-attention-v1″, action=store_true, help=”enable older version of split attention optimization that does not consume all the VRAM it can find”)
parser.add_argument(“–use-cpu”, nargs=+,choices=[SD, GFPGAN, BSRGAN, ESRGAN, SCUNet, CodeFormer], help=”use CPU as torch device for specified modules”, default=[])
parser.add_argument(“–listen”, action=store_true, help=”launch gradio with 0.0.0.0 as server name, allowing to respond to network requests”)
parser.add_argument(“–port”, type=int, help=”launch gradio with given server port, you need root/admin rights for ports < 1024, defaults to 7860 if available”, default=None)
parser.add_argument(“–show-negative-prompt”, action=store_true, help=”does not do anything”, default=False)
parser.add_argument(“–ui-config-file”, type=str, help=”filename to use for ui configuration”, default=os.path.join(script_path, ui-config.json))
parser.add_argument(“–hide-ui-dir-config”, action=store_true, help=”hide directory configuration from webui”, default=False)
parser.add_argument(“–ui-settings-file”, type=str, help=”filename to use for ui settings”, default=os.path.join(script_path, config.json))
parser.add_argument(“–gradio-debug”, action=store_true, help=”launch gradio with –debug option”)
parser.add_argument(“–gradio-auth”, type=str, help=set gradio authentication like “username:password”; or comma-delimit multiple like “u1:p1,u2:p2,u3:p3”, default=None)
parser.add_argument(“–gradio-img2img-tool”, type=str, help=gradio image uploader tool: can be either editor for ctopping, or color-sketch for drawing, choices=[“color-sketch”, “editor”], default=”color-sketch”)
parser.add_argument(“–opt-channelslast”, action=store_true, help=”change memory type for stable diffusion to channels last”)
parser.add_argument(“–styles-file”, type=str, help=”filename to use for styles”, default=os.path.join(script_path, styles.csv))
parser.add_argument(“–autolaunch”, action=store_true, help=”open the webui URL in the systems default browser upon launch”, default=False)
parser.add_argument(“–use-textbox-seed”, action=store_true, help=”use textbox for seeds in UI (no up/down, but possible to input long seeds)”, default=False)
parser.add_argument(“–disable-console-progressbars”, action=store_true, help=”do not output progressbars to console”, default=False)
parser.add_argument(“–enable-console-prompts”, action=store_true, help=”print prompts to console when generating with txt2img and img2img”, default=False)
但根据github的默认方法,还是通过使用的时候直接修改省事。
使用
通过前面的安装配置,你就可以通过你设置的端口进行访问。
访问内容后分为几个大的模块;
txt2img — 标准的文字生成图像;img2img — 根据图像成文范本、结合文字生成图像;Extras — 优化(清晰、扩展)图像;PNG Info — 图像基本信息Checkpoint Merger — 模型合并Textual inversion — 训练模型对于某种图像风格Settings — 默认参数修改
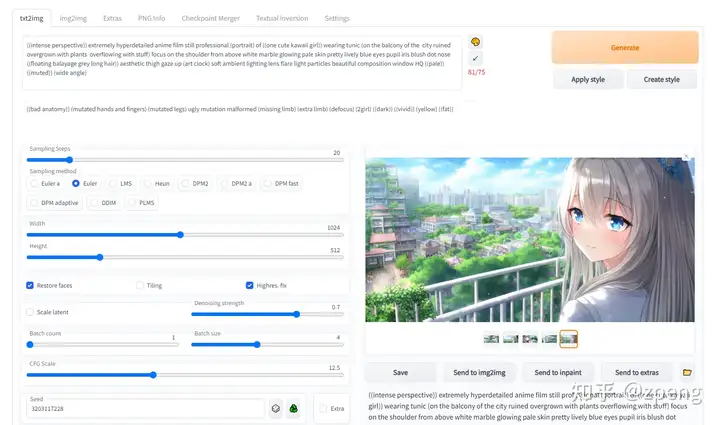
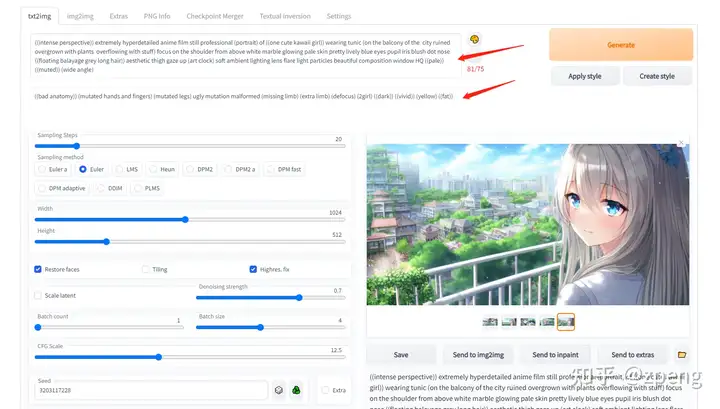
txt2img部分介绍
内容输入部分:
prompt 该部分主要就是对于图像进行描述,有内容风格等信息进行描述。后面的画板可以一些随机的风格、下面箭头是之前任务的参数;
Negative prompt 这个主要是提供给模型,我不想要什么样的风格;特别对于图上出现多个人的情况,就可以通过2girls等信息进行消除;
优化方法部分:
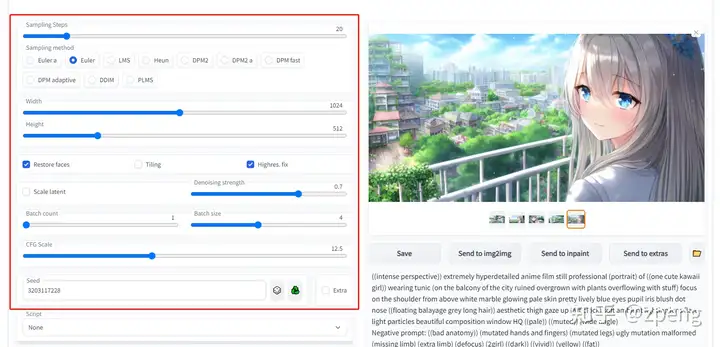
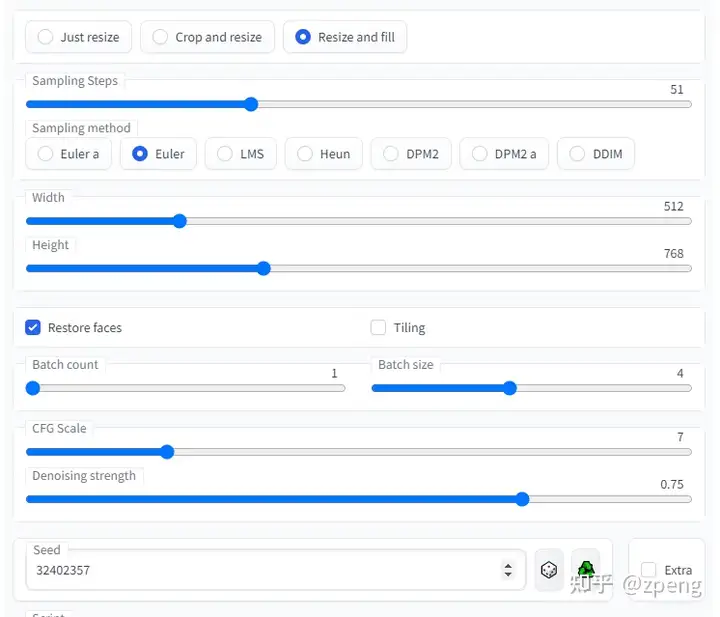
Sampling Steps diffusion model 生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去比对 prompt 和 当前结果,去调整图片。更高的步数需要花费更多的计算时间,也相对更贵。但不一定意味着更好的结果。当然迭代步数不足(少于 50)肯定会降低结果的图像质量;
Sampling method 扩散去噪算法的采样模式,会带来不一样的效果,ddim 和 pms(plms) 的结果差异会很大,很多人还会使用euler,具体没有系统测试;
Width、Height 图像长宽,可以通过send to extras 进行扩大,所以这里不建议设置太大[显存小的特别注意];
Restore faces 优化面部,绘制面部图像特别注意;
Tiling 生成一个可以平铺的图像;
Highres. fix 使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数 Scale latent 在潜空间中对图像进行缩放。另一种方法是从潜在的表象中产生完整的图像,将其升级,然后将其移回潜在的空间。Denoising strength 决定算法对图像内容的保留程度。在0处,什么都不会改变,而在1处,你会得到一个不相关的图像;
Batch count、 Batch size 都是生成几张图,前者计算时间长,后者需要显存大;
CFG Scale 分类器自由引导尺度——图像与提示符的一致程度——越低的值产生越有创意的结果;
Seed 种子数,只要中子数一样,参数一致、模型一样图像就能重新;
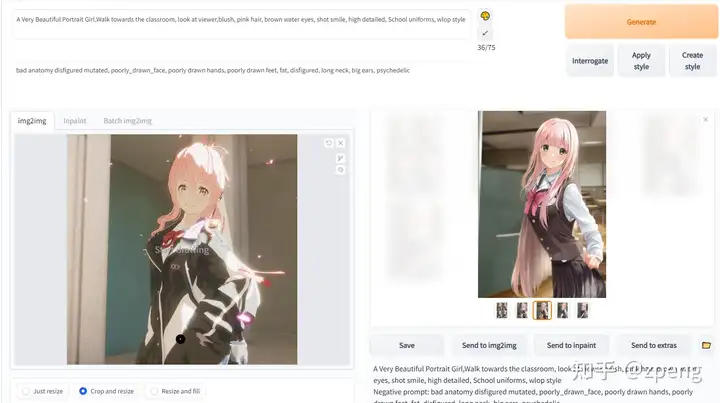
img2img部分介绍
这部分参数很多与txt2img类似,这里主要说明一下不同部分;
内容输入部分:
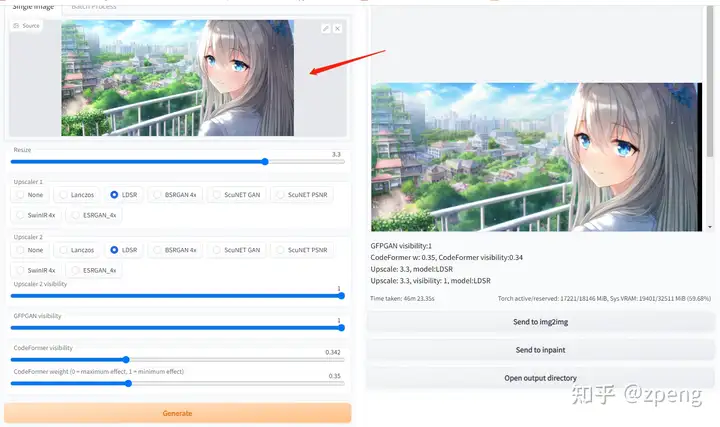
这里主要增加的是要模仿的图片,可以是手绘的、也可以是类似的;
其他文字信息类似,这里依然是描述越准确越好;
对于其中参数主要是图像是否要保存相同尺寸:
Just resize、 Crop and resize、 Resize and fill 这三种模式保证图输出效果,因为下面会有新的尺寸,是填充还是性对应缩放;
调整部分
这部分大部分参数与上面一致,主要新增加的是:
Denoising strength 与原图一致性的程度,一般大于0.7出来的都是新效果,小于0.3基本就会原图缝缝补补;
Extras部分介绍
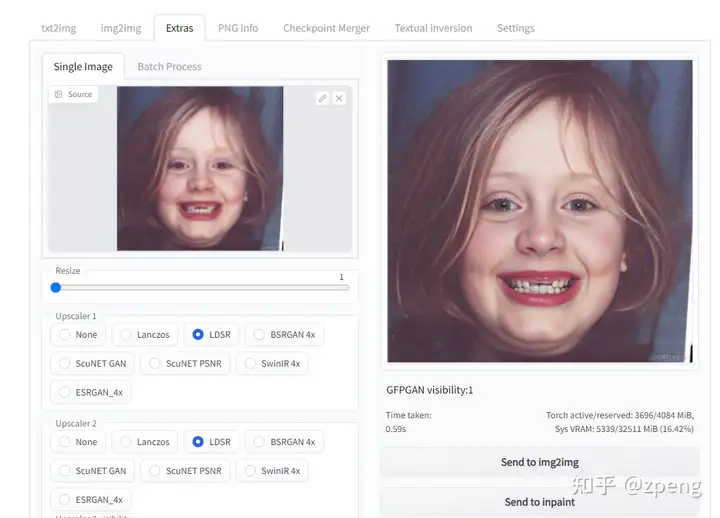
该部分主要将图像进行优化,其中很多方法的模型使用的时候会自动下载,很容易下载失败导致报错。
图片导入,也可以通过其他模块中的send to extras直接使用;
下面相关参数主要是对于图像的优化等工作,具体使用大家可以自己测试。
GFPGAN visibility 主要就是对于图像清晰度进行优化,例如下图:
其他参数使用不多,这里不做过多介绍。
PNG Info部分介绍
该部分主要说明图像大小等信息。
后面的几个模块基本是调整模型何如何训练新的prompt的,这里就不做过多说明。























暂无评论内容