
关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
From 机器之心
在这篇博客文章中,美国数字媒体公司 BuzzFeed 的数据科学家 Max Woolf 做了一项实验,证明 Negative Prompt可以改善 Stable Diffusion 2.0 的图像生成质量。
StabilityAI 前段时间发布了StableDiffusion2.0
。这一全新版本的出现颠覆了整个 AI 生态系统。从架构上看, Stable Diffusion 2.0 与之前的 V1 版本基本相同,只是采用了新的文本编码器(OpenCLIP 而非 OpenAI 的 CLIPText)。Stability AI 宣称 Stable Diffusion 2.0 在算力方面的表现更为优异,但艺术始终是主观的。

在发布后的 24 小时内,Reddit 和 Twitter 用户注意到,在完全相同的输入 prompt 和设置下,新模型的性能比 Stability Diffusion 1.5 要差。一些用户还注意到,输入GregRutkowski等在世艺术家的名字对输出结果没有任何影响(Greg Rutkowski 的名字是一个著名的文本 prompt,之前可以让 Stable Diffusion迅速生成Rutkowski风格的绘画,这遭到了Greg Rutkowski本人的质疑)。

Greg Rutkowski说,“我在AI工具上遇到的问题是缺乏版权。没有人问他们是否可以用我的工作来训练这些程序。我认为这些工具不应该使用在世艺术家的作品。这是一种不受控制或监管的版权侵犯,是对人权的侵犯。我听说风格是不能有版权的,但我认为在某种程度上应该有。”
一些人指出,新模型的训练样本减少了NSFW(NotSuitableForWork)图像的数量,因而导致了这些变化(因为新模型使用NSFW filter 过滤掉一些不可描述的内容)。但在我看来,主要问题在于新版本使用了 OpenCLIP。采用新的文本编码器意味着适用 Stable Diffusion 早期版本的一些假设和 prompt hack 可能失效。另一方面,这又可能引发新的 prompt hack。比如,Stability AI 首席执行官 Emad Mostaque 提到,考虑到模型训练的方式,否定形式的 prompt(negative prompt)应该会更有效。尽管这仍是理论,但真正的实践效果往往更好。
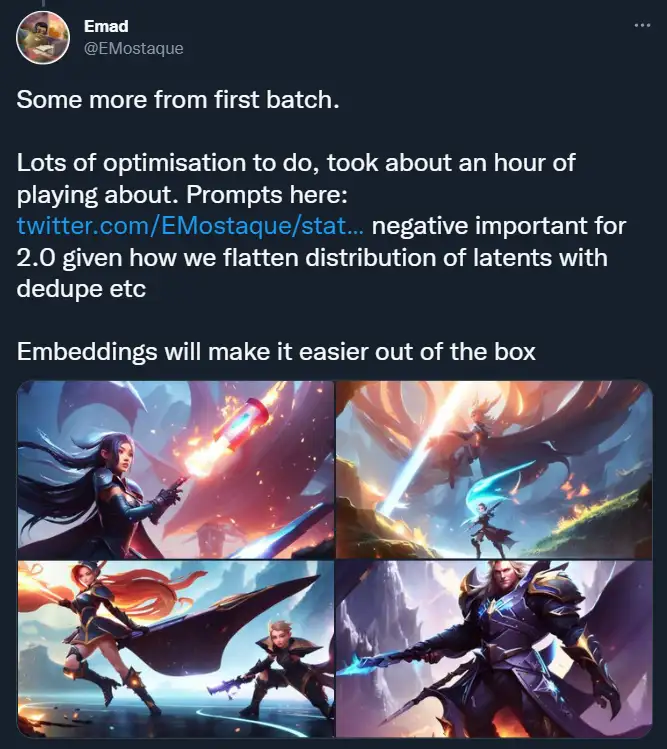
我之前没怎么在 Stable Diffusion 上弄过negativeprompt,尽管有传言称这是某些知名商用 Stable Diffusion 服务背后的秘籍。在用 SD 2.0 对negativeprompt 进行大量实验之后,我发现,negativeprompt 对于从模型中获取良好结果着实意义重大。而最令人惊讶的是,negativeprompt 可能远远优于传统 prompt addition。
什么是negativeprompt?
首先我们简单解释一下什么是 negative prompt。与正常的文本到图像 prompt 类似,Negative Prompting 表示你不希望在结果图像中看到的术语。这个强大的功能允许用户从原始生成的图像中删除任何对象、样式或异常。尽管 Stable Diffusion 以人类语言的形式接受被称为 prompt 的输入,但它很难理解否定词,如「no, not, except, without」等。因此,用户需要使用 negative prompting 来完全控制 prompt。
再就是关于 prompt 权重的问题。
Prompt 权重是 Stable Diffusion 支持的一项技术,可以让用户精细地控制他们的 prompt。使用 prompt 权重,用户可以告诉 Stable Diffusion 哪里应该多关注,哪里应该少关注。
例如 Prompt :柴犬和北极熊(占 0.7)的混合体。由于给北极熊赋予了更多权重,所以在输出图像中看到北极熊特征占主导地位。

我们用 Stable Diffusion 2.0 来测试一下。先回到我的 VQGAN+CLIP prompt(参见:https://minimaxir.com/2021/08/vqgan-clip/),看看它生成的达利风格的赛博朋克森林是个什么样子:

注:达利是西班牙超现实主义画家,代表作品有《记忆的永恒》等。

达利代表作品《记忆的永恒》。
假如你想删除树或某种颜色(如绿色),那么这两者(trees、green)就是在 negative prompt 中要写的内容。例如下图中,prompt 为「cyberpunk forest by Salvador Dali」;negative prompt 为 「trees, green」。

prompt:cyberpunk forest by Salvador Dali;negative prompt: trees, green
虽然充斥着大量超现实主义赛博朋克隐喻,这依然是一片森林。
从理论上来说,要改进上述图像,一个很流行的技巧是纳入更抽象的不良图像概念,如模糊和马赛克。但是,这些negativeprompt 是否比其他“成分”(如 4k hd)更好呢?negativeprompt 如何与那些 positive promt addition 相互作用?我们来进一步实际测试一下。
negativeprompt 和 positive prompt 会碰撞出什么火花?
这里插句题外话。有种名为 textual inversion 的技术(可供文本编码器学习特定对象或风格,可以在 prompt 中轻松调用)在 Stable Diffusion 2.0 中同样适用,尽管由于文本编码器不同(更大,嵌入是 1024D 而非 768D),每个 textual inversion 嵌入都必须重新训练,但在其他方面表现相同。
SD1.X 中的一种常见风格是 “Midjourney” 风格(见下图),有种过度幻想的美学意味。我还训练了 <midjourney> token 的新版本(参见:https://huggingface.co/minimaxir/midjourney_sd_2_0)。

此外, textual inversion 或许还可以创新地运用于negativeprompt。Redditor Nerfgun3 为 SD1.X 训练了一个“否定嵌入”,具体来说就是通过将通常的negativeprompt 用作 positive prompt 来生成合成图像数据集,然后在其上训练 textual inversion 嵌入。我做了一些调整来再现这个过程,改进了合成数据集,进而训练出一个新的 <wrong> token。
现在我们对positive prompt addition(positive token)与negativeprompt(negativetoken)进行交叉测试,看看negativeprompt 的影响力有多大。以下是要测试的 prompt 列表,其中 positive prompt 为绿色,negativeprompt 为红色:

例如,Stable Diffusion 2.0 的一项测试输入可能是「cyberpunk forest by Salvador Dali, in the style of <midjourney>」以及一个negativeprompt「in the style of <wrong>」分别对应绿色 “TOKEN” prompt 标签和红色“TOKEN” 标签。
此外,每个单独生成的图像将以相同的初始潜态开始,同时进行 seeded 调度。这样能更清楚地显示negativeprompt 的影响,因为在恒定初始潜态下保持相同 prompt 可以使生成的图像成分在negativeprompt 改变的情况下保持不变。
现在总算可以开始了。那就让我们以 Steve Jobs 的头像为基本 prompt 开始吧,相当简单。

base prompt: Steve Jobs head, seed: 59049
两个 prompt addition 都改变了风格;base prompt 生成的是卡通图像;写实的 prompt addition 使其更像是 3D 渲染,而 Midjourney token 又使其成为一种艺术手法。然而,当加入negativeprompt,每张图像都更清晰,模糊度降低,色调呈中性,皮肤细节也更丰富。值得一提的是, <wrong> token 要优于较小的negativeprompt。
再来看一个经典的图像生成:用 original DALL-E 演示的著名牛油果扶手椅,怎么样?

有趣的地方在这儿,positive 文本 prompt addition 完全破坏了原始 prompt 意图,而每个negativeprompt 却更加精准地完善了相应图像(包括整个牛油果!)
演示都很不错,我们再次回到达利风格的赛博朋克森林:

base prompt: cyberpunk forest by Salvador Dali, seed: 59049
在这个示例中,两个 positive prompt 都抹杀了达利的风格,倾向于更写实的森林,随后又为negativeprompt 所强化。在原始 prompt 下,negativeprompt 更能突显达利的艺术风格。这个例子充分说明,positive prompt addition 并不一定就是好的。
negativeprompt 能否帮助 AI 生成美味食物的图像?就像 DALL-E 2 可以实现的那种?我们看能不能生成一个汉堡:

这个示例相当清楚地展示了negativeprompt 对得出最终结果大有帮助;使用两个 token 的结果输出逼近 DALL-E 2 的质量!
Stable Diffusion 2.0 另一个有意思的地方是文本渲染效果更好;小字不一定完全清晰,但大字更容易辨认。或许 Stable Diffusion 2.0 可以生成一篇《纽约时报》(NYT)头版文章来描绘机器人霸主的崛起。

尽管潜在输入固定,但 Stable Diffusion 2.0 还是生成了很多种不同类型的邪恶机器人,报纸版式可以说很 NYT。如此怪异的仅由negativeprompt 文本生成的图像表明一种非常罕见模式的崩溃,这挺有趣(或者说是 Stable Diffusion 在隐藏某些东西)。
我们还可以研究一下negativeprompt 如何帮助渲染人类对象。我们来看看 Taylor Swift。如果她成了 Taylor Swift 总统会怎么样?(希望 Stable Diffusion 不会把她和其他 Taylor 总统搞混)

两种 positive prompt addition 得到的初始输出都明显更差,令人意外。但negativeprompt 又一次解决了问题,为 Taylor 总统换了几套华服。值得注意的是,与 SD 1.X 相比,Stable Diffusion 2.0 生成的手更逼真…… 不过也不能细看。
最后,不能忘了《刺猬索尼克》中那个刺猬 Ugly Sonic,也是我上一篇 Stable Diffusion 博文的主题(参见:https://minimaxir.com/2022/09/stable-diffusion-ugly-sonic/)。上一次,我收到很多控诉,说 AI 生成的 Ugly Sonic 并不是真正的 Ugly Sonic,因为生成的 Ugly Sonic 没有人类牙齿!是时候解决这个问题了!

在这个示例中,negativeprompt 破坏了 Ugly Sonic,因为把他的人类牙齿一步步去除了!
结论
在 AI 艺术中,我们总会有不同收获,不过negativeprompt 将是 AI 图像生成领域的一个有力工具。固守曾用的 prompt 策略这种做法不太对。这也给了我们一个很好的机会,摆脱在世艺术家提供的这根 prompt 设计拐杖,因为拄拐难行。这对整个行业来说也是一件好事(尤其是考虑到法律的不确定性!)。
我用于生成本文图像的所有代码都可以在一个 GitHub 库中找到(参见:https://github.com/minimaxir/stable-diffusion-negative-prompt),其中有一个 Colab Notebook,用于 <wrong> token 下的常规生成,还有一个 Colab Notebook 用于 3×3 标记的网格图像,都能轻松调整 prompt 输入,你自己也可以在其中实验。
原文链接 https://minimaxir.com/2022/11/stable-diffusion-negative-prompt/
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
最新论文解析
NeurIPS2022 Spotlight | TANGO:一种基于光照分解实现逼真稳健的文本驱动3D风格化
ECCV2022 Oral | 微软提出UNICORN,统一文本生成与边框预测任务
NeurIPS 2022 | VideoMAE:南大&腾讯联合提出第一个视频版MAE框架,遮盖率达到90%
NeurIPS 2022 | 清华大学提出OrdinalCLIP,基于序数提示学习的语言引导有序回归
SlowFast Network:用于计算机视觉视频理解的双模CNN
WACV2022 | 一张图片只值五句话吗?UAB提出图像-文本匹配语义的新视角!
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索


















暂无评论内容