

作者丨维克多
Transformer的提出距离我们已经有5年的时间,随着模型规模的不断增长,性能提升也逐渐出现边际效益递减的情况。如何训练出最优性能的大模型?

最近,DeepMind做了一项调查,想弄清AI语言模型的规模和token之间的关系。这个小组训练了超过400个模型,规模从7000万参数到160亿参数不等,token数量从50亿到5000亿不等。
该小组发现,模型参数大小和token的数量成正相关,换句话说,当模型规模加倍的时候,token也应该加倍。
1
如何得到这种关系?
目前确实是大模型时代,自从1750亿参数的GPT-3横空出世时,勾起了研究员的兴趣。近两年的时间,业界陆续推出了好几个模型,且一个比一个大,并且在多数任务上获得了令人令人深刻的性能。
但这种超越认知的性能表现,是以巨大的计算和能源消耗为代价,业界也一直在讨论这种代价是否值得。例如前谷歌研究员Timnit Gebru就曾撰写论文讨论“AI 语言模型是否太大以及科技公司在降低潜在风险方面做得是否足够。”她也因为该论文被谷歌解雇。
大模型的训练预算一般是提前计划好的,毕竟训练一次成本太大。因此,在给定预算的条件下,准确估计最佳模型超参数变得非常关键。之前,也有学者已经证明参数的数量和自回归语言模型(autoregressive language model)的性能之间存在幂律关系。
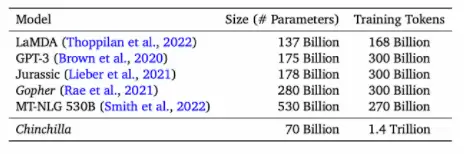
例如先前的研究表明,10倍计算预算对应增加5.5倍模型规模,以及1.8倍的token数量。但这项研究表明:模型大小和token的数量应该成等比例增长。
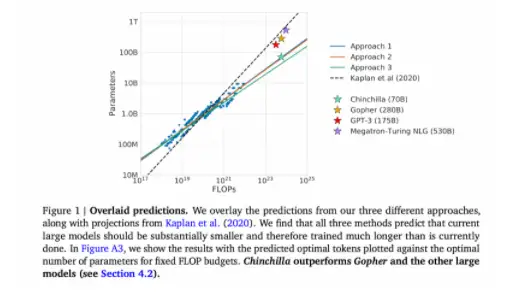
此外,研究员还预测,对于训练Gopher(2800亿个参数的语言模型),最佳模型应该小4倍,并且应该在大4倍的token上进行训练。这一预测,在包含1.4万亿个token的 Chinchilla中的训练得到验证。Chincilla的性能优于Gopher,由于模型规模减小,推理成本也更低。
2
如何让大模型更加高效?
大模型只有在大数据集上才能发挥最大的效力,同时,DeepMind也注意到,处理大数据集时需要格外小心,训练集和测试集的合理划分,才能最小化语言建模损失以及最优赋能下游任务。
研究界必须考虑与此类大型模型相关的伦理和隐私问题。正如过去所讨论:从网络上收集的大型数据集包含有毒的语言、偏见和私人信息。
关于大模型如何更高效的问题,近日,清华大学刘知远从模型架构层面也提出了看法《清华刘知远:大模型「十问」,寻找新范式下的研究方向》,他表示:
随着大模型越变越大,对计算和存储成本的消耗自然也越来越大。最近有人提出GreenAI的概念,即需要考虑计算能耗的情况来综合设计和训练人工智能模型。面向这个问题,我们认为,随着模型变大,AI会越来越需要跟计算机系统进行结合,从而提出一个更高效面向大模型的支持体系。一方面,我们需要去建设更加高效分布式训练的算法,在这方面国内外都有非常多的相关探索,包括国际上比较有名的DeepSpeed 以及悟道团队在开发的一些加速算法。
另一个方面,大模型一旦训练好去使用时,模型的“大”会让推理过程变得十分缓慢,因此另外一个前沿方向就是如何高效将模型进行尽可能的压缩,在加速推理的同时保持它的效果。这方面的主要技术路线包括剪枝、蒸馏、量化等等。同时最近我们发现,大模型里面具有非常强的稀疏发放的现象,这对于模型的高效压缩和计算有着非常大的帮助,这方面需要一些专门算法的支持。

雷峰网




















暂无评论内容