
Pine 发自 凹非寺
量子位 | 公众号 QbitAIAI搜索引擎再度进化?!
给这个AI一个主题,分分钟给你甩出一篇论文综述,而且还会自己提供论文引文。
又或者输入一个科学类的名词,AI也能迅速生成这个名词专属的维基百科。
这个AI名叫Galactica (简称:GAL),是最新开源的一个科学语言大模型,把AI转化为科学生产力。
并且还实现了学科“大一统”,数学、物理、计算机…这个AI都能用。
模型刚一放出,就迅速引发网友热议,目前相关推文已有近15万浏览,累计点赞、转发、引用也已破五千。
Facebook前技术官也出来为它来站台。
还有网友亲自体验了一把,写出来的文献综述“看起来相当不错”,甚至直呼:
下一步它是不是就能产生新想法了。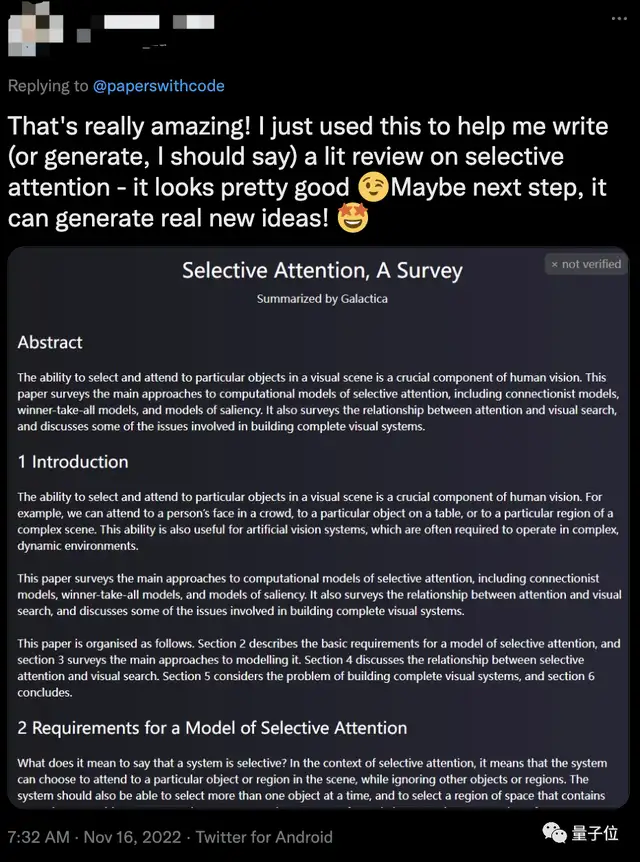
其实写文献综述和生产维基百科还只是GAL功能的一部分,除去这些,它还能回答一些专业问题、编写科学代码、注释分子和蛋白质……
具体效果如何,一起来看看吧~
可以作为科学生产的工具
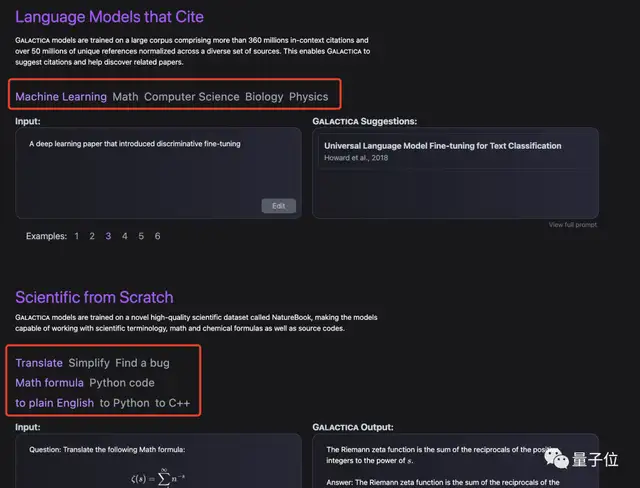
提到科学生产力,就肯定离不开论文的查找,这不,GAL帮你解决了。
它涵盖了五种科学学科:机器学习、数学、计算机科学、生物以及物理。
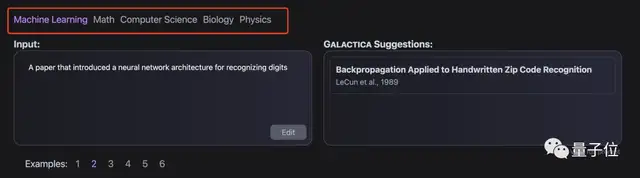
选择好学科,然后在左边框输入想要找的论文主题,右边GAL便会推荐最合适的论文以供阅读。
除了推荐论文之外,GAL还有一个更加实用的功能:生成讲稿。
比如说要做个关于密度泛函理论(DFT)的pre,又懒得写讲稿,直接GAL一下,分分钟搞定(手动狗头)。
GAL还能够用来注释分子和蛋白质,如下就是GAL生成的RDKit(可生成用于机器学习的分子描述符)操作手册。
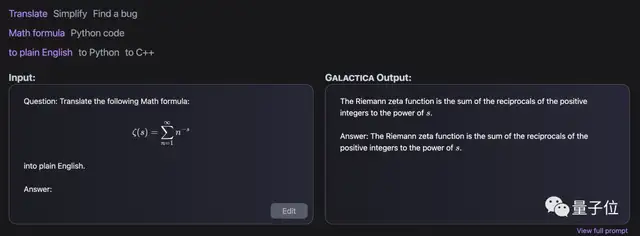
在一些细节问题上,GAL也狠狠拿捏了!
就比如说你看不懂一些复杂的数学公式和代码,没关系交给GAL来解决,它能直接给你翻译成大白话。
不仅如此,它还能实现数学公式和代码之间的相互转换,或者不同类型代码之间的转换。
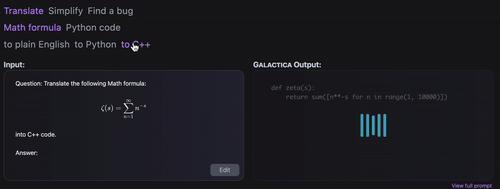
更重要的是,他还有简化公式和查错功能。
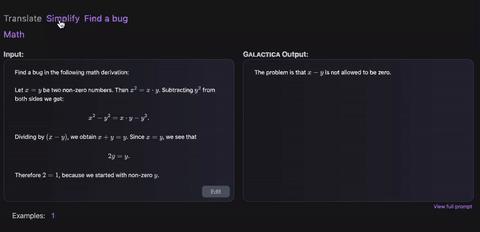
怎么做到的?
GAL能实现这么复杂的功能,就不得不提到它的训练数据集。
据官方消息,GAL是在一个名为NatureBook的新型高质量科学数据集上进行训练的,这使模型能够使用科学术语、数学和化学公式以及源代码。
其中包括超过4800万篇论文、教科书和课堂讲稿,还有数百万计的化合物和蛋白质、科学网站以及百科全书等等。
除此之外,为了查找论文并规范化引用,GAL的数据集中包含超过3.6亿条上下文引用和超过5000万条跨不同来源规范化的独特参考。
有了这么庞大的数据集之后,那接下来便面临两个问题。
第一个问题是如何管理这些高质量的数据集,实现这点,GAL用了两步:
所有数据都以一种通用的标记格式进行处理,打通各种来源数据之间的壁垒。预训练中包含用于特定任务的数据集,这就能保证在处理特定任务时能够更加专业。还有一个问题是:如何设计界面交互?
首先就像上文提到的那样,GAL能够支持不同类型的任务。
因此在设计界面交互时便对各种任务进行分类,不同的分类会支持不同的类型的数据。
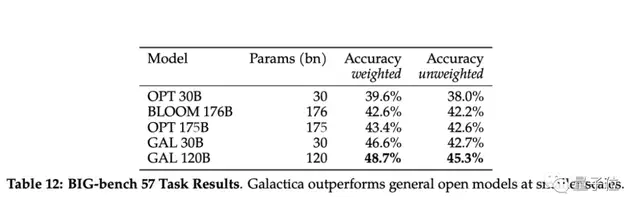
既然GAL拥有高度管理和高质量的科学数据集,那和其他模型相比效果如何?
直接上数据!
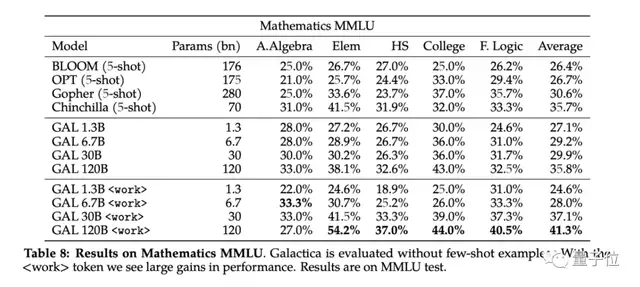
推理方面,GAL的优势脱颖而出,在数学MMLU(大规模多任务语言理解)上,表现要优于Chinchilla,数学方面,表现也优于PalM 540B和GPT-3 175B。
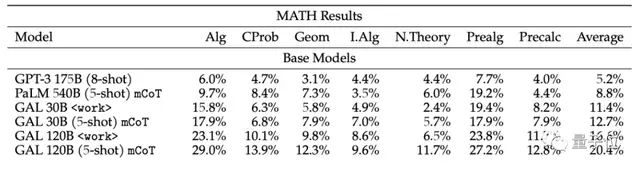
尽管,GAL并没有经过一般数据集的训练,但它在BIG-bench上的表现仍旧优于BLOOM和OPT-175B。
看完之后是不是也心痒痒了,先码住再说!
传送门:
https://galactica.org/参考链接:
[1]https://twitter.com/paperswithcode/status/1592546933679476736[2]https://github.com/paperswithcode/galai[3]https://galactica.org/static/paper.pdf—完—
@量子位 · 追踪AI技术和产品新动态
深有感触的朋友,欢迎赞同、关注、分享三连վᴗ ի




















暂无评论内容