
关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
机器之心编辑部
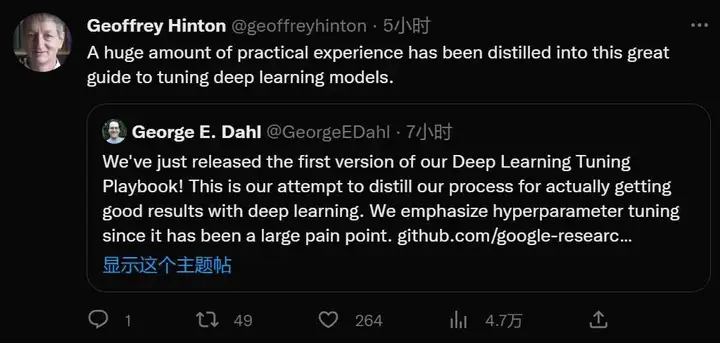
「大量的实践经验已被提炼成这份强大的深度学习模型调参指南。」——Geoffrey Hinton。众所周知,AI 的超参数决定着模型学习效果和速度。相比普通机器学习任务,深度学习需要的训练时间较长,因此调参技巧就显得尤为重要。
但鉴于深度学习「炼丹」的特性,不同的模型需要不同的超参数,而每个超参的意义又不同,在不同实验中,参数和调整的方向又都不一样。调参这件事一直以来没有固定的套路,每个人都有自己的经验,因此经常会出现一些似是而非的理论,比如:
Random seed = 0 得到坏的结果
Random seed = 42 得到好的结果
为了破除「迷信」,高举科学旗帜,近日来自谷歌大脑、哈佛大学的研究人员发布了《Deep Learning Tuning Playbook》,旨在帮助大家解决这一 AI 领域的老大难问题。
项目 GitHub 上线仅一天就已收获了上千 Star 量:
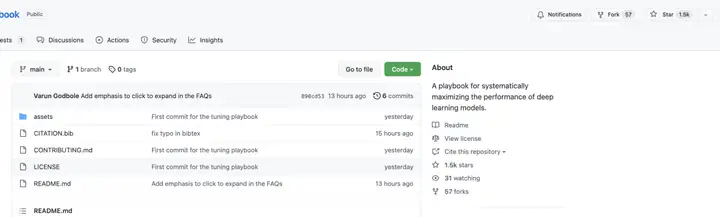
项目地址:https://github.com/google-research/tuning_playbook
该项目也得到了图灵奖获得者,谷歌 AI 科学家 Geoffrey Hinton 等人的转推支持。Geoffrey Hinton 表示「大量的实践经验已被提炼成这份强大的深度学习模型调参指南。」
文档意义
这份调参指南适用于对改进深度学习模型性能感兴趣的工程师和研究人员。阅读这份指南需要掌握机器学习和深度学习的基本知识。
这份指南的主要内容是调整超参数,也涉及深度学习训练的其他方面,例如 pipeline 实现和优化。指南假设机器学习问题是一个监督学习问题或自监督学习问题,但其中的一些规定也适用于其他类型的问题。
当前,深度神经网络就像一个黑箱,要想在实践中获得良好的性能,需要付出大量的努力和猜测。更糟糕的是,很少有人记录各种研究获得良好结果的实际方法。人们似乎在回避详解实践中的调参问题,也极少分享经验。这让深度学习专家获得的实验结果,与普通从业者复现相似方法获得的结果差距悬殊。
随着深度学习方法的成熟并对世界产生重要影响,深度学习社区需要更多涵盖有用方法的资源,包括对于获得良好结果至关重要的所有实用细节。
本项目是一个由五名研究人员和工程师组成的团队,他们在深度学习领域工作多年,其中一些人早在 2006 年就开始了。

该团队已经将深度学习应用于从语音识别到天文学的各个领域的问题,并在此过程中学到了很多东西。本文档源于工程师们训练神经网络、教授新机器学习工程师以及为同事提供深度学习实践建议的经验。虽然深度学习早已从实验室实践的机器学习方法发展为数十亿人使用的技术驱动产品,但它作为一门工程学科仍处于起步阶段。
该指南是谷歌研究人员在构建自有深度学习方法时产生的,它代表了作者在撰写本文时的观点,而不是任何客观规律。为此,作者鼓励发现其中存在问题的读者提出替代建议和令人信服的证据,以便不断更新完善这份指南。
需要说明的是,这不是 TensorFlow 等谷歌产品的官方支持文档。
指南内容
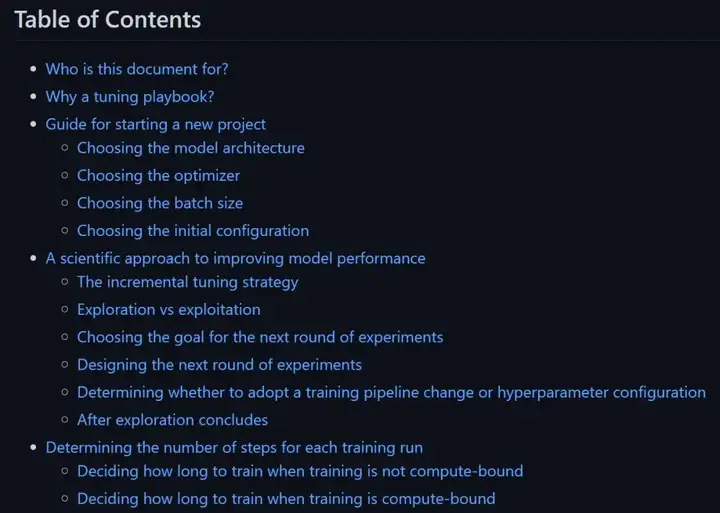
该指南包含哪些内容?可以分为四大部分:
指导开始新项目
改善模型性能的科学方法
如何决定每次训练运行步数
训练过程中的其他经验
例如第一部分,你开始新项目时如何选择模型架构、优化器、batch 大小等,都有详细的经验指导。

该指南中关于选择模型架构的经验。
而后关于「炼丹」的模型性能改进、训练运行的步数等也有经验分享。
可以说,这份指南可以教你提升模型性能的大量细节。看完下面目录,大家可以去Github细致学习下。

往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
【CV知识点汇总与解析】| 技术发展篇 (超详细!!!)
最新论文解析
NeurIPS2022 Spotlight | TANGO:一种基于光照分解实现逼真稳健的文本驱动3D风格化
ECCV2022 Oral | 微软提出UNICORN,统一文本生成与边框预测任务
NeurIPS 2022 | VideoMAE:南大&腾讯联合提出第一个视频版MAE框架,遮盖率达到90%
NeurIPS 2022 | 清华大学提出OrdinalCLIP,基于序数提示学习的语言引导有序回归
SlowFast Network:用于计算机视觉视频理解的双模CNN
WACV2022 | 一张图片只值五句话吗?UAB提出图像-文本匹配语义的新视角!
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索



















暂无评论内容