
语言模型是根据已知文本生成未知文本的模型。自GPT-3以来,大型语言模型展现出了惊人的zero-shot和few-shot能力,即不改变参数仅改变输入的in-context learning。这是与此前流行的finetune范式截然不同的新范式。近期的ChatGPT,更是让文本生成从以前人们眼中的玩具,逐渐展现出了生产力工具的潜质。本系列文章会介绍大型语言模型相关的重要论文,以期与更多的人一起熟悉这一新的范式。
作为系列的第一篇文章,Emergent Abilities of Large Language Models显得格外合适。本文展现了语言模型的增大(scale up)并非只是提高了一两个点的指标,而是发生了质变,突变式地拥有了小语言模型所不具有的新能力。这才是scale up的意义所在。
本系列争取一周更新一篇(希望不要咕咕)。欢迎大家关注~也欢迎大家在评论区发表观点
1. 涌现
涌现可以用一句经典的话来概括:量变引起质变。如智能就是一种涌现现象,我们很了解单个神经元的电生理反应,但智能并不蕴含于单个神经元之中。而当大量的神经元相互交互,“智能”却在其中产生了。整体并不简单等于部分之和,其会具有组分所不具有的新功能。涌现有时是很难解释的,毕竟如果我们能解释清楚神经元是如何涌现出的智能,人工智能也就完成大半了。
具体到语言模型上,涌现的能力指在小模型时并不具有,表现接近随机,而在模型规模越过一个阈值时,表现突然提升。
2. 大语言模型的新能力
为了观察新能力是如何在模型规模跨过阈值时产生的,首先我们需要有衡量模型规模的指标:使用训练FLOPs和模型参数量是很自然的想法。需要注意的是,我们无法用一个指标来衡量所有影响模型的因素。两个模型可能有同样的FLOPs,但有不同的模型参数量(如MoE)。此外,数据集的质量,优化的好坏也会影响模型的表现。这使得我们无法得到一个具体的涌现发生的规模阈值。
论文关注的涌现能力是模型的prompting(in-context learning)能力,这是大型语言模型最核心的能力。Prompting是指不需要通过训练改变模型参数,仅需在输入中添加文本(如对任务的描述),使模型在此基础上补充回答。一句话概括结论:prompting相关的能力是随着模型规模的增大而涌现的。下面将从few-shot prompting和augmented prompting strategies两方面进行介绍。
2.1 Few-shot Prompting
Few-shot prompting是给出若干个输入-输出对作为prompt,模型需对新输入补充输出。这可能是目前最常见的prompting方法。
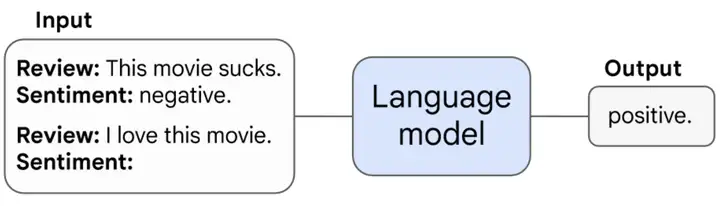
如下图所示,许多任务随着模型规模跨过阈值而可以被few-shot prompting解决,包括:加减乘除(A),基于知识的问答(G)等。有趣的一点是,在以训练FLOPs为规模指标时,各模型、各任务的涌现阈值均在 102210^{22} 量级左右。这就像生物只有大脑足够大才能有高级智能一样,许多高级能力只有在模型达到一定规模时才能获得。
2.2 Augmented Prompting Strategies
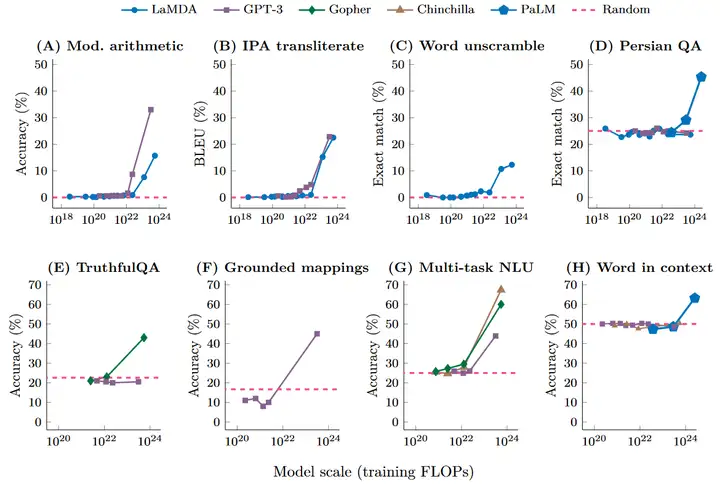
除了few-shot prompting以外,还有其他prompting或者finetuning策略可以进一步增加语言模型的能力。比如说对于涉及多步推理和计算的任务,如果让语言模型直接生成答案,往往效果不佳。但通过prompting时给出逐步思考的范例(chain of thought),抑或finetune模型来预测中间过程(scratchpad),都能大幅提高模型表现。限于篇幅,本文不会详细地去介绍这些方法的具体细节,留待以后的文章介绍(挖坑)。
如下图所示,augmented prompting strategies同样只在模型规模跨过一定阈值后起正面作用,对于小模型甚至起负面作用。
3. 关于Scaling的思考
3.1 更大
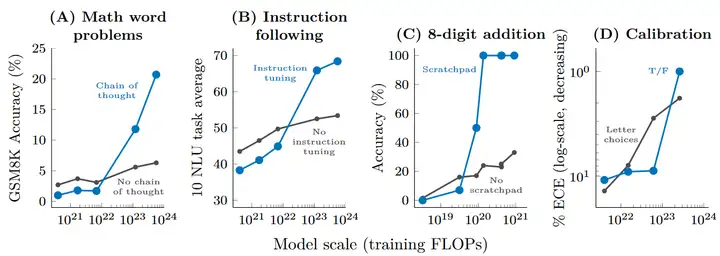
BIG-Bench是一个包含超过200个任务的用于评测语言模型的数据集,其中并非所有的任务都会发生涌现(如下图所示)。有的任务表现随scale up而平滑增加,而有的任务至今为止还没有通过scale up超过随机表现。比如同为算术类任务,simple arithmetic会平滑增加,modified arithmetic发生了涌现,multistep arithmetic还没有超过随机表现。
这些未解决的任务会是进一步研究的对象。这些问题是否能单纯靠scale up解决?涌现的原因是什么?涌现之后scale up是否有性能上限?即使scale up在性能提升上不会遇到瓶颈,计算的负载也会成为巨大的问题。
3.2 更小
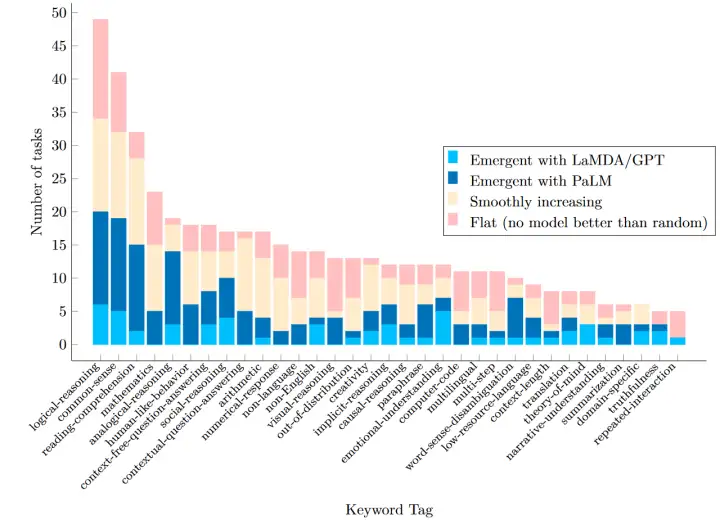
影响模型能力的不仅有模型的规模,还有数据、模型结构或是训练方法。在更好的数据、模型结构、训练方法下,我们可以在同样甚至更小的模型规模下实现更好的效果。
使用更好的数据可以在更低的模型规模下实现涌现:如PaLM 62B以更少的模型参数与更低的FLOPs,突破了LaMDA 137B和GPT-3 175B只能取得随机表现的多个任务。虽然因为高昂的训练成本,不可能进行详尽的消融实验,但一个可能的原因是PaLM使用了更好的数据(如多语言数据、代码数据)。数据本身可能也是涌现的原因,如数据中的长程依赖、稀有类别与few-shot prompting的涌现有关,chain of thought能力可能来自于代码数据[1]
更好的模型结构也可以降低涌现的阈值。如encoder-decoder模型要更适合于instruction finetuning[2]。对于decoder模型,instruction finetuning仅对68B以上参数量的模型有效。但encoder-decoder模型仅需要11B。
Emergent Abilities of Large Language Models是一篇总结性的工作,对过往文献中的结论进行了整理,从涌现的角度进行了概括:模型的量变产生了质变。




















暂无评论内容