

一百多年前,数学家安德烈.马尔可夫突发奇想,想要探索普希金的诗体小说《叶甫盖尼.奥涅金》中的语言的统计规律,从而模拟普希金的写作风格。在研究过程中,马尔可夫使用了一种概率模型,将文本中的单词和短语联系起来,以此来预测下一个单词或短语的可能性。
后来,这种方法被命名为马尔可夫链(Markov Chain),在众多的科学技术领域得到了广泛应用。或许,马尔可夫提出了人类历史上最早的大语言模型的构想。
而我们今天所讨论的大语言模型,主要是基于一种叫作Transformer的神经网络构架。Transformer是由Google Brain团队发明的,他们的论文Attention Is All You Need现在已经有6万多次引用。相比传统的循环神经网络(RNN)和卷积神经网络(CNN),Transformer具有更好的并行性,能够更快地训练和预测。
Transformer的核心是自注意力机制(self-attention),它能够根据输入的文本序列中不同位置之间的相对距离,动态地计算出每个位置与其他位置的注意力权重。通过这种机制,Transformer能够捕捉文本中不同位置之间的依赖关系,从而在处理长文本时具有出色的表现。(这里强烈推荐图解Transformer!)
当然了,Transformer也不是凭空产生的。2014年Bengio等人的一篇很重要的论文,Neural Machine Translation by Jointly Learning to Align and Translate 提出的一种新型神经机器翻译方法。具体地说,Bengio引入了一种新的机制来解决神经机器翻译中的一个关键问题——如何将源语言的每个单词对应到目标语言的每个单词。
该方法通过在每一步预测目标语言的单词时,自适应地对源语言的每个单词进行加权,从而对齐源语言和目标语言的单词。该权重由神经网络动态计算,而不是通过手动对齐来实现。这种机制使得神经网络可以更好地处理长句子和复杂结构。
Transformer沿用了Bengio的编码器-解码器架构,将源语言文本映射到目标语言文本。编码器通过循环神经网络对源语言文本进行编码,将其转化为一个固定长度的向量表示。解码器则通过循环神经网络对目标语言文本进行生成,从编码器的向量表示中提取信息,以逐步生成目标语言文本。
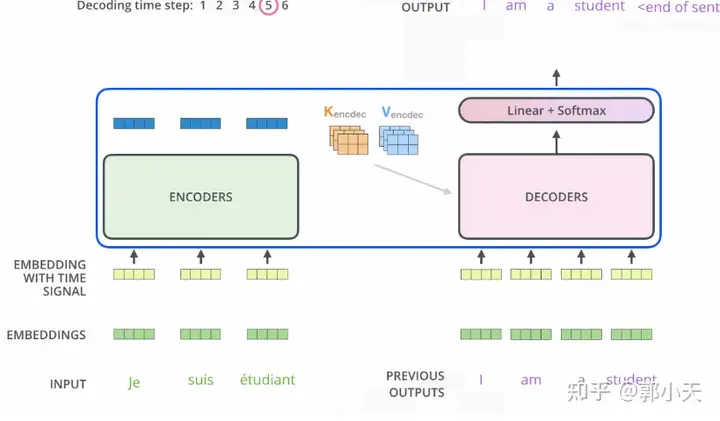
值得注意的是,Bengio的这篇论文提出的注意力机制,也成为Transformer中自注意力机制的灵感来源之一。Transformer使用了自注意力机制和残差连接等技术,大大拓展了Bengio的编码器-解码器构架,使得模型不仅仅用于机器翻译任务,而是成为一个真正意义上的大语言模型。
按照最初的Transformer架构,大型语言模型的发展开始分为两个方向:编码器式的Transformer用于预测建模任务,如文本分类;解码器式的Transformer用于生成建模任务,如翻译、摘要和其他形式的文本创作。
在提出Transformer不到一年的时间,Google便将Transformer成功落地,也就是BERT。BERT的创新点在于采用双向Transformer结构,使得模型能够同时考虑前后上下文,更好地捕捉语言的语义和语法信息。BERT的出现震撼了当时整个人工智能领域,在此之前人们普遍认为人工智能在CV上会比在NLP上有更大的可能。但BERT改变了这一切。
BERT的成功给了人们一个重要的启示,那就是使用更大规模的数据和更复杂的模型预训练,可以显著提高模型表现。于是,同样在2018年,第一代GPT登场了。
GPT采用了单向Transformer解码器,在大规模文本语料上进行无监督的预训练,学习到通用的语言表示。预训练阶段使用了一个语言建模任务,即给定部分文本序列,预测下一个单词。
但区别于BERT最重要的一点倒不是GPT的单向解码器(而BERT则是双向编码器-解码器),他们最重要的区别恨不能就写在GPT的脸上——Generative Pre-Train——生成式预训练,它的名字就说明了一切。而BERT则是判别式预训练。
判别式预训练和生成式预训练,主要体现在目标函数上的差别。
判别式预训练是指利用未标记数据预训练一个判别式模型来提高监督学习任务的性能。判别式模型的预训练目标是根据输入序列预测序列的标签。具体来说,判别式预训练方法对输入序列进行编码,然后使用解码器来预测输入序列的标签。这个过程可以用公式表示:
P(y1,y2,…,yn|x1,x2,…,xn)=∏i=1nP(yi|x1,x2,…,xn,y1,y2,…,yi−1)P(y_1,y_2,…,y_n|x_1,x_2,…,x_n)=\prod_{i=1}^{n}P(y_i|x_1,x_2,…,x_n,y_1,y_2,…,y_{i-1})
其中,x1,x2,…,xnx_1,x_2,…,x_n 表示输入序列, y1,y2,…,yny_1,y_2,…,y_n 表示标签序列, P(yi|x1,x2,…,xn,y1,y2,…,yi−1)P(y_i|x_1,x_2,…,x_n,y_1,y_2,…,y_{i-1}) 表示对应于自编码器的解码器输出的概率分布。
生成式预训练(Generative Pre-Training)是指利用未标记数据预训练一个生成式模型来提高自然语言生成任务的性能。生成式模型的预训练目标是预测下一个词语或字符。具体来说,生成式预训练方法使用自回归模型对输入序列进行建模,然后使用最大似然估计来预测输入序列的下一个词语或字符。这个过程可以用以下公式表示:
P(x1:n)=∏i=1nP(xi|x<i)P(x_{1:n})=\prod_{i=1}^{n}P(x_i|x_{<i})
其中, x1:nx_{1:n} 表示输入序列, P(xi|x<i)P(x_i|x_{<i}) 表示对应于自回归模型的输出概率分布。
借用李沐老师的类比就是,BERT只是会帮你做完形填空,而GPT则是预测你下一个词会是什么。显然,GPT的任务难度更大,并且会在更多场合派上用场。
在上世纪50年代,香农接过马尔可夫未竟的伟大构想,用利用信息熵的概念来解决语言模型中的问题。他认为可以将语言看作是一个离散信源,每个词语都是一个符号,而每个符号出现的概率可以通过历史状态计算得到。因此,可以使用马尔科夫模型来建立语言模型,预测下一个词语的出现概率。这或许是人类历史上第一个成型的语言模型。
而如今,Transformer发明至今不过短短数年,基于Transformer的大语言模型已成蔚然大观。
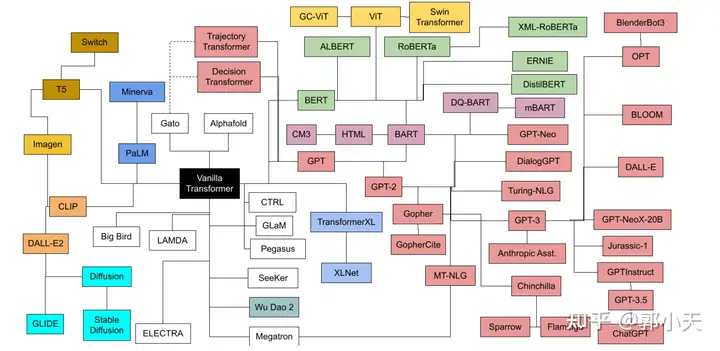
巨人在一百年前就在等着人类走到今天了。





















暂无评论内容