
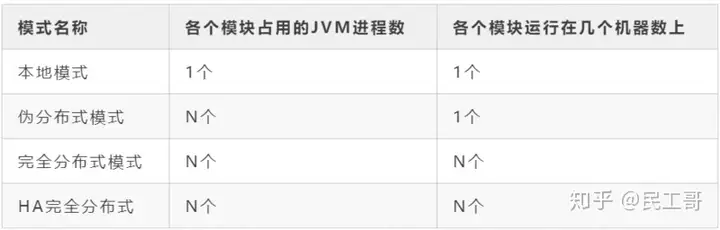
2.2 HDFS系统部署
2.2.1 HDFS集群简介
一个典型的HDFS集群通常由一个NameNode节点,一个Secondary NameNode节点,和若干个DataNode节点组成。
本集群搭建案例,以5个节点为例进行搭建,节点部署规划如下:
主机名
节点类型
hdp20-01 NameNode
hdp20-02 Secondary NameNode
hdp20-03 DataNode
hdp20-04 DataNode
hdp20-05 DataNode2.2.2 HDFS集群安装详解
1、上传Hadoop安装包
使用SecureCRT软件连接到集群中的5个linux服务器节点,在hdp20-01的会话窗口上使用快捷键Alt+P 打开SFTP窗口,将Hadoop安装包拖动到SFTP窗口(或输入put命令)即可上传,上传后,安装包文件位于当前登录用户root的主目录中,如图所示:
![图片[1]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic1.zhimg.com/80/v2-f5ff2646e73e7da1205ef7b2fd4e92f4_720w.webp)
图2.29 上传Hadoop安装包
- 解压Hadoop安装包并修改配置文件
解压命令如下:
tar -zxf hadoop-2.8.1.tar.gz -C /usr/local/apps/进入Hadoop配置文件路径
cd /usr/local/apps/hadoop-2.8.1/etc/hadoop/- 修改配置文件
(1)配置Hadoop的通用配置文件
vi core-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp20-01:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/app/hadoop-2.8.1/tmp_data</value>
</property>
</configuration>参数说明:
fs.defaultFS:用于指定Hadoop的默认文件系统为HDFS,并通过value中的URI:hdfs://hdp20-01:9000/ 来指定HDFS的NameNode服务进程所在机器为hdp20-01,及客户端请求NameNode时所用的端口为9000
hadoop.tmp.dir:用于指定Hadoop(包括HDFS)的服务进程在运行过程中存放一些临时数据的目录
(2)配置HDFS的核心配置文件
vi hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.rpc-address</name>
<value>hdp20-01:9000</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp20-02:50090</value>
</property>
</configuration>参数说明:
dfs.namenode.rpc-address:指定namenode进程启动时所绑定的主机名及绑定的端口;
dfs.replication:指定运行在本机的客户端上传文件到HDFS时所保存的副本数量;
dfs.secondary.http.address:指定Secondary NameNode进程所部署的节点。
(3)配置从节点列表文件
vi salvehdp20-03
hdp20-04
hdp20-05提示
使用脚本命令start-dfs.sh启动集群时,该脚本需要读取这个文件,来获知需要在哪些节点上启动DataNode服务进程,因此,需要将规划为DataNode节点的主机名全部列入该文件中。
(4)配置Hadoop环境变量
vi hadoop-env.sh在文件末尾添加:
export JAVA_HOME=/usr/local/app/jdk1.8.0_60/
export Hadoop_HOME=/usr/local/apps/hadoop-2.8.1说明:JAVA_HOME即为集群各机器上的jdk安装目录;
4、将配置好的Hadoop程序目录拷贝到集群中其他节点
在hdp20-01机器上,通过scp命令,将配置好的安装包远程拷贝到其他机器
scp -rq =/usr/local/apps/hadoop-2.8.1 hdp20-02:/usr/local/apps/
scp -rq =/usr/local/apps/hadoop-2.8.1 hdp20-03:/usr/local/apps/
scp -rq =/usr/local/apps/hadoop-2.8.1 hdp20-04:/usr/local/apps/
scp -rq =/usr/local/apps/hadoop-2.8.1 hdp20-05:/usr/local/apps/- 修改系统环境变量
为了便于执行Hadoop安装目录中的各脚本命令,需要在系统环境变量中配置Hadoop_HOME变量,及在PATH变量中增加Hadoop中的bin路径和sbin路径,具体操作如下:
vi /etc/profile在末尾添加Hadoop_HOME,和修改PATH变量,如下:
export apps=/usr/local/apps
export JAVA_HOME=$apps/jdk1.8.0_60/
export Hadoop_HOME=$apps/hadoop-2.8.1/
export PATH=.:$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$Hadoop_HOME/bin:$Hadoop_
HOME/sbin将配置文件同步给其他节点:
scp /etc/profile hdp20-02:/etc/
scp /etc/profile hdp20-03:/etc/
scp /etc/profile hdp20-04:/etc/
scp /etc/profile hdp20-05:/etc/2.2.3 HDFS集群初始化
NameNode在第一次启动之前,需要生成初始状态的元数据存储目录,生成初始状态的元数据镜像文件等,因此,在第一次启动HDFS集群之前,需要用HDFS的格式化命令,来执行上述操作,详情如下:
在NameNode所在的节点(hdp20-01)上,输入如下命令进行格式化:
hdfs namenode -format出现如下提示表示格式化成功:
![图片[2]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-83da2bd7181b7b80abfefea046226aa3_720w.webp)
2.2.4 HDFS集群启动和关闭
1、手动启动方式
HDFS集群的启动,本质上就是在各节点上启动相应的服务进程,比如,在hdp20-01上启动NameNode进程,在hdp20-02上启动Secondary NameNode进程,在hdp20-03、hdp20-04、hdp20-05上分别启动DataNode进程。
HDFS提供了启动服务进程的脚本命令(hadoop-daemon.sh),具体操作如下图示:
(1)启动NameNode
![图片[3]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-1184308c9435add02e56cb23d3460a65_720w.webp)
- 启动Secondary NameNode
![图片[4]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic1.zhimg.com/80/v2-2e50e0829466171109fa28a893b6304c_720w.webp)
- 启动hdp20-03节点的DataNode
![图片[5]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-c33c964d3e305258278c3fdde0003809_720w.webp)
- 启动hdp20-04节点的DataNode
![图片[6]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-df2ad141c2cf65b1b49c7ac554ffaf0d_720w.webp)
- 启动hdp20-05节点的DataNode
![图片[7]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-2f06a12ba0188a6d8b075c370d5eb7a7_720w.webp)
提示:上面可以直接使用 hadoop-daemon.sh命令是因为将Hadoop的sbin目录加入到了path环境变量中
2、手动方式关闭集群
将上面的命令由start改为stop则可以停用相应的进程
[root@hdp20-01~]# hadoop-daemon.sh stop namenodestopping namenode
[root@hdp20-02~]# hadoop-daemon.sh stop secondarynamenode stopping secondarynamenode
[root@hdp20-03~]# hadoop-daemon.sh stop datanode stopping datanode
[root@hdp20-04~]# hadoop-daemon.sh stop datanode stopping datanode
[root@hdp20-05~]# hadoop-daemon.sh stop datanodestopping datanode
3、脚本方式自动批量启动&停止集群
(1)自动化脚本启动集群:手动的方式主要是用于体验和理解HDFS的启动机制,当集群节点数量很多时,手动的方式肯定难以胜任,所以,一般都是使用HDFS安装包中提供的一键式批量管理脚本start-dfs.sh和stop-dfs.sh来启动和停止集群。
该脚本本质是根据配置文件向指定的机器发送上面的ssh指令:
- 根据fs.defaultFS配置发送:
hadoop-daemon.sh start namenode- 根据slaves配置文件,逐个发送:
hadoop-daemon.sh start datanode- 根据dfs.secondary.http.address配置发送指令:
hadoop-daemon.sh start secondarynamenode所以start-dfs.sh命令可以在hadoop集群的任意一台节点上启动(不过需要配置SSH好免密登陆):
[root@hdp20-01~]# start-dfs.sh Starting namenodes on [hdp20-01]
hdp20-01: starting namenode, logging to /usr/local/apps/hadoop-2.8.1/logs/hadoop-root-namenode-hdp20-01.out
hdp20-03: starting datanode, logging to /usr/local/apps/hadoop-2.8.1/logs/hadoop-root-datanode-hdp20-012.out
hdp20-04: starting datanode, logging to /usr/local/apps/hadoop-2.8.1/logs/hadoop-root-datanode-hdp20-013.out
hdp20-05: starting datanode, logging to /usr/local/apps/hadoop-2.8.1/logs/hadoop-root-datanode-hdp20-01.out
Starting secondary namenodes [hdp20-02]
hdp20-02: starting secondarynamenode, logging to /usr/local/apps/hadoop-2.8.1/logs/hadoop-root-secondarynamenode-hdp20-012.out
批启动脚本执行完毕后,可以到各节点上检查进程是否运行:
[root@hdp20-01 ~]# jps2989 Jps
2816 NameNode
[root@hdp20-02~]# jps2866 Jps
2772 SecondaryNameNode
[root@hdp20-03 ~]# jps2307 Jps
2108 DataNode
[root@hdp20-04~]# jps2307 Jps
2108 DataNode
[root@hdp20-05~]# jps2307 Jps
2108 DataNode
说明hdfs的进程都正确启动
(2)自动化脚本停止集群:
批量停止集群的脚本命令为:stop-dfs.sh,可在任意一个节点上执行该命令,演示如下:
[root@hdp20-013 ~]# stop-dfs.sh Stopping namenodes on [hdp20-01]
hdp20-01: stopping namenode
hdp20-03: stopping datanode
hdp20-04: stopping datanode
hdp20-05: stopping datanode
Stopping secondary namenodes [hdp20-02]
hdp20-02: stopping secondarynamenode
- HDFS提供的web控制台
Name Node提供了一个查看HDFS集群状态的web服务,绑定的端口默认为50070,因此,我们可以在任何一台能与Name Node节点联网的机器上,使用web浏览器查看HDFS集群状态,如图所示:
![图片[8]-Hadoop系列4–HDFS集群搭建实战之HDFS系统部署-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-e49b043bc4377b44d30d8305d48e2182_720w.webp)
图2.36 Hdfs Web UI

















暂无评论内容