
前言
寒假花了很多时间在基于Giraph的PageRank这个实验上面,最终实现的效果是在服务器上的分布式环境中使用Giraph这个框架运行PageRank算法。这个系列的文章主要是把在配置Hadoop的过程中所有踩过的坑和解决方法记录总结一下,希望能为后来者提供一点帮助和借鉴,也欢迎和大家交流。(俺也是小白,轻喷~)
Hadoop伪分布式环境搭建
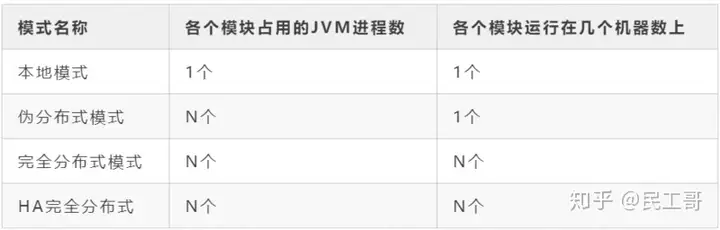
首先介绍一下Hadoop的三种运行模式:
Standalone单机模式:不进行集群的配置,使用本地文件系统。Pseudo-Distributed伪分布式模式:在单机上模拟集群的配置方式,使用HDFS文件系统,节点只有1且为本机。Fully-Distributed完全分布式模式:在多台服务器上部署,使用HDFS文件系统,拥有多个节点。
虽然我的最终目的是在服务器的集群上配置Hadoop并运行Giraph程序,但是我还是先在本机上配置伪集群Hadoop测试Demo吧,对于想在自己电脑上运行Giraph程序的朋友们也可以配置伪集群模式。
1. 环境准备
我选择的Hadoop版本是Hadoop2.5.1,大家可以根据自己的需要自行选择Hadoop的版本。
另外配置Hadoop环境还需要的是Java。这样来看的话我们需要的东西如下
Java8:Java SE Development Kit 8Hadoop2.5.1:Hadoop-2.5.1
2. Java环境
Java环境这个不用多说,我下载的文件名是jdk-8u281-linux-x64.tar.gz。这里使用8的原因是过高的Java版本在Hadoop2上启动节点的时候可能会报Warning,这个Warning在Hadoop3之后的版本被解决了[1][2],所以要么你Java版本和Hadoop版本都很高,要么都不高。。
(1) 解压缩
如果你下载的文件后缀跟我一样也是.tar.gz,请使用命令解压缩
(2) 配置环境变量
下面需要vim编辑模式的基本知识,最最简单的
按i进入insert模式,左下角出现INSERT时可以编辑编辑后使用:wq保存修改并退出
下载Java之后就是配置$JAVA_HOME环境变量
JAVA_HOME的路径这里有点小区别,如果是Mac你的Java_Home应该是
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/
export PATH=${JAVA_HOME}/bin:$PATH
source .zshrc或.bash_profile
但是在服务器上配置Java_Home时,则是:
export JAVA_HOME=/home/czj/jvm/jdk1.8.0_221
export PATH=${JAVA_HOME}/bin:$PATH
source .bashrc
主要区别在Java_HOME的路径,大家根据自己的情况注意一下。
(3) 验证环境变量
最后想要达到的效果是使用命令
能够得到
![图片[1]-Hadoop环境配置(一):Pseudo-Distributed模式-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-7407cb42029c3a966d157ec8af96b745_720w.webp)
成功输出的话就配置完成了Java。
3. Hadoop环境
(1) 先解压
(2) 配置环境变量
export HADOOP_HOME=”/your_path/hadoop-2.5.1″
export HADOOP_CONF_DIR=”$HADOOP_HOME/etc/hadoop”
export PATH=$PATH:$HADOOP_HOME/bin
source ~/.bash_profile
(3) 验证环境变量
终端输入
如果你看到
![图片[2]-Hadoop环境配置(一):Pseudo-Distributed模式-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-6efc542c12026c1e311e0a039532b32f_720w.webp)
那么环境变量就配置完成了
(4) 修改Hadoop配置文件
这一步算是最复杂的吧,不过伪分布式的配置文件还好,真正吐血的是Hadoop集群的配置,这里我们先介绍伪分布式如何配置,这部分参考了[3][4]
需要修改的配置文件如下,这些配置文件在/hadoop-2.5.1/etc/hadoop/目录下
core-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xmlhadoop-env.sh
其中1、2、5是必须要配置的,本文配置3、4是为了配置yarn,之后如果需要在集群配置,最好还是要配置yarn来管理节点,所以在这里先模拟一下吧。
core-site.xml
<property>
<name>fs.defaultFS</name> <!–配置访问 nameNode 的 URI–>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <!–指定临时目录,否则系统重启的时候可能会删除默认路径下的文件–>
<value>/usr/local/Cellar/hadoop-2.5.1/tmp</value>
</property>
</configuration>
hdfs-site.xml
<property>
<name>dfs.replication</name> <!–配置文件的副本数量–>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value><!–关闭防火墙–>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/Cellar/hadoop-2.5.1/data/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/Cellar/hadoop-2.5.1/data/data</value>
</property>
</configuration>
mapred-site.xml
这个文件需要手动创建
在hadoop-2.5.1/etc/hadoop/下使用scp命令或mv命令
然后再打开mapred-site.xml
<property>
<!–指定mapreduce运行在yarn上–>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8088</value>
</property>
</configuration>
(我也不知道为啥 是个网址)
这里是需要为该shell脚本配置JAVA_HOME和Hadoop_CONF_DIR,因为Hadoop无法识别环境变量(有待考证), 这两个路径根据你自己设置的路径来
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_261.jdk/Contents/Home/
export HADOOP_CONF_DIR=/usr/local/Cellar/hadoop-2.5.1/etc/hadoop
在启动之前需要把tmp文件夹建好,即core-site.xml中tmp的路径(DataNode和NameNode文件夹在系统允许的情况下会自己生成)
(5) 格式化namenode
这三个文件夹都建好之后,在终端使用命令
或者(我在服务器上用的是下面这条命令,应该是不同版本的相同命令)
倒数几行出现has been successfully formatted就成功了
如果环境变量出现了问题,可以直接进入Hadoop的目录/Hadoop-2.5.1,使用下面这条命令
(6) 启动HDFS
进入Hadoop-2.5.1目录
使用命令
即可启动HDFS和Yarn
注:如果没有配置免登录,这里可能会要求多次输入密码,配置免登录的步骤在后面介绍完全分布式Hadoop配置时再给出,如果大家等不及可以看我给的几篇参考文章或自行百度。
(7) 验证
启动完使用jps命令检查,以下节点都启动成功了就说明没问题了
![图片[3]-Hadoop环境配置(一):Pseudo-Distributed模式-卡咪卡咪哈-一个博客](https://pic3.zhimg.com/80/v2-122d0eeaea248e17571db9da3608750a_720w.webp)
如果NameNode或者DataNode没启动(经常有的情况),说明最近的几个步骤有问题,请删除data和tmp文件,然后新建一个tmp文件夹,重新执行hadoop namenode -format
最后
进入yarn管理页面http://localhost:8088/cluster/nodes
显示
![图片[4]-Hadoop环境配置(一):Pseudo-Distributed模式-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-6e588d9f93b744bfe61ade250c3634f9_720w.webp)
显示
![图片[5]-Hadoop环境配置(一):Pseudo-Distributed模式-卡咪卡咪哈-一个博客](https://pic2.zhimg.com/80/v2-872a7a5e5436903494ec73079b82eeb5_720w.webp)
那么就大功告成啦!
尾
本篇文章仅介绍Hadoop伪分布式环境的配置,下一篇会讲如何在服务器上配置Hadoop集群。最后就是祝新年快乐啦~

















暂无评论内容