
为什么要用Hadoop?
1.源码开源
2.社区活跃,参与者很多
3.涉及到分布式存储和计算的方方面面:
Flume进行数据采集
Spark/MR/Hive等进行数据处理
HDFS/HBase进行数据存储
4.已经得到企业界的验证
Hadoop相关网址:
Hadoop: http://hadoop.apache.org
Hive: http://hive.apache.org
Spark: http://spark.apache.org
HBase: hbase.apache.org
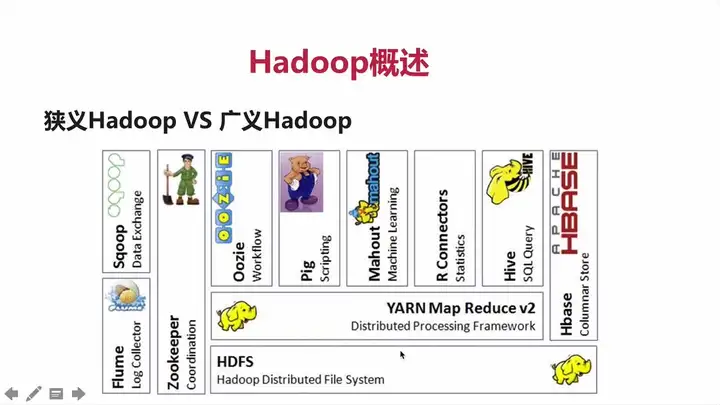
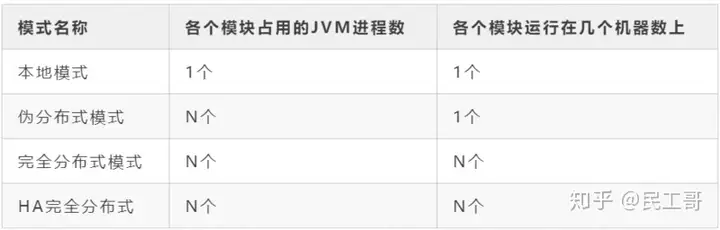
Hadoop常用工具
分布式文件系统HDFS
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
基于Google的GFS论文,很多大数据框架都是基于Google的论文,包括Spark。
论文发表于2003年,HDFS实际上是GFS的克隆版。HDFS的设计目标
非常巨大的分布式文件系统
运行在普通廉价的硬件上
易扩展,为用户提供性能不错的存储服务
HDFS架构图
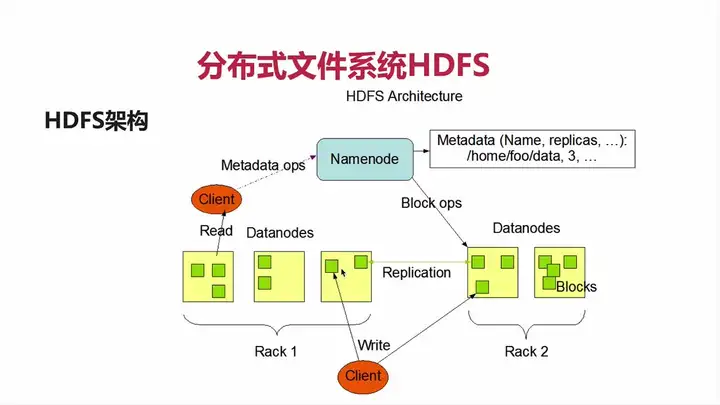
HDFS是一个 master/slave 的架构,一个 master 会带 N 个 slave。在大数据框架里是非常常见的,包括HDFS/YARN/HBase。
一个HDFS的集群通常由一个NameNode和多个DataNodes构成。master就是NameNode,slave就是DataNode。
master的主要功能
1.管理文件系统的namespace。
2.调节客户端访问文件系统里的文件。
slave的主要功能
1.管理文件存储到节点上。
2.HDFS有一个文件系统的namespace,允许用户的数据存放在HDFS上面。
3.一个文件会被拆分成多个block,有一个blockSize属性,默认是128M。如果有一个130M的文件,将会被拆分成两个文件,一个128M一个2M。这些blocks被存储在多个DataNodes上面。
NameNode:
NameNode执行的是一个文件系统的namespace。
namespace包括
1.关闭,打开,重命名一个文件,或重命名一个目录。
2.决定了我们的blocks存在哪一个DataNode上面。
DataNode
1.从文件系统客户端的请求中,读和写。
2.也会负责block的创建,删除,以及block的备份(replication upon)工作。
NameNode主要是负责文件系统的操作,DataNode负责block的一些操作。
总结
NameNode
1.负责客户端请求的响应
2.负责元数据(文件的名称、副本系数、Block存放的DataNode)的管理。
DataNode
1.存储用户文件对应的数据块(Block)
2.要定期向NameNode发送心跳信息,汇报本身及其存储的block信息,健康状况。
元数据就是图中的部分

client
就是你的一些操作,比如Java API文件,或者HDFS的Shell文件。

HDFS典型架构
NameNode和DataNode设计的理念就是,能够运行在一些非常廉价的机器上面,这些机器都是Linux系统。
HDFS的开发构建都是基于Java语言的,任何能够运行Java的机器,都能够运行NameNode或者是DataNode的软件。
典型的架构就是,一台机器上面运行一个NameNode,其他机器可以选择一台机器运行一个DataNode,或一台机器运行多个DataNode,但是在实际生产环境中,是不建议一台机器运行多个DataNode。
HDFS副本机制
HDFS支持传统的层级目录架构,就相当于我们的Windows文件夹,C盘下有一个A文件夹,A下面又有一个B文件夹,一层一层的。
一个用户或者一个程序可以创建目录和存储文件到指定的目录里面去。这种层级的文件系统命名空间,和我们已有的系统都是很类似的,Windows,Mac等。能够创建,删除,重命名文件,或移动一个文件到一个目录。
NameNode维护的是,文件系统的命名空间(namespace)。对namespace做的任何操作和修改,都会被NameNode记录下来。创建一个文件,修改名字,移动文件等,都是对namespace的修改。
一个应用程序可以指定一个文件的副本系数是多少,这些都会被我们的HDFS管理起来。
一个文件的拷贝数量,就叫做副本因子,或者副本系数(replication factor)。
这些信息,都会被存储在NameNode里面。Data Replication 数据副本
HDFS是一个高可靠的存储非常大的文件,而且这些文件是夸节点的,在一个集群里面。一个文件会被分割成很多块,存储在节点里面。一个文件会被拆分成一个有序的blocks。这些blocks都是以多副本的方式存储的,为了容错。因为如果只存储在一个节点上,那个节点挂掉就没办法访问了。如果是多副本存储,及时其中的几个节点不能访问了,其他节点依然能正常访问blocks的副本。
block的大小和replication factor都是可以针对一个文件来单独配置的。
一个文件里所有的block,除了最后一个block以外,其他的大小都是一样的。
一个应用程序能够指定一个文件的副本系数,可以在创建文件的时候指定,也可以在后面进行相应的修改。
HDFS里面的文件是 write-once
只能写一次,除非是追加或者是截断。并且,有严格的要求,在任意时间内,只能有一个write,不支持多并发写。
NameNode还要决定所有block的副本操作,它会周期性的从集群中的每个DataNode那里接收一个Heartbeat(心跳) 和 一个 Blockreport(块的汇报)
Heartbeat告诉NameNode自己还活着,Blockreport告诉NameNode自己机器上块的一些情况。
如图所示:
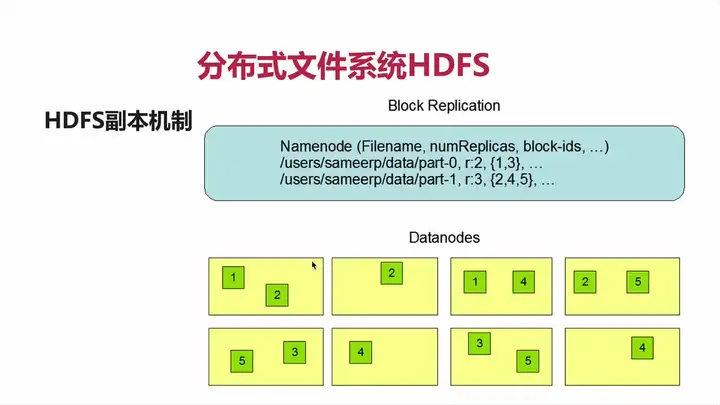
Blockreport包括上面的信息
Filename: 表示文件的名字
numReplicas: 代表副本系数
block-ids: 代表block的编号
/users/sameerp/data/part-0, r:2, {1,3}, …
表示part-0这个文件,有2个副本,编号是1,3。
每个黄色的代表一个机器,1这个副本,在两台机器上都有存储,即使其中一台挂了另一台的也可以继续使用。
同理,下面的part-1文件,有3个副本,编号是2,4,5。
分别在三台机器上都有存储,即使其中的两台挂掉,也不影响使用。
官方文档: http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html


















暂无评论内容