
一、搭建本地环境
1、下载准备两个工具
Hadoop-2.7.3.tar.gz
Hadoop-2.7.3-winutils.exe.rar
![图片[1]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t015a473f0c211870b3.webp)
2、将Hadoop-2.7.3-winutils.exe.rar解压后,其中的两个文件进行拷贝
Hadoop.dll
Wintuils.exe
![图片[2]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t013e025dd07ec1b689.webp)
3、将Hadoop-2.7.3.tar.gz解压后,找到bin目录,把上面的两个文件Hadoop.dll、Wintuils.exe拷贝到当前位置
![图片[3]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t0126ec81a01cedf5db.webp)
4、配置Hadoop的环境变量
![图片[4]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01137ea8a1610420bf.webp)
5、找到Hadoop中的日志文件log4j.properties拷贝到我们新建的Eclipse中的Maven项目中,这个日志文件是方便我们使用的,不需要写太多的配置,直接借用Hadoop中文件内容,也可以自己创建该日志文件,编写里面的内容。
(1)Hadoop中日志文件的位置
![图片[5]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01dc689e9706deecd0.webp)
(2)拷贝到Eclipse中项目的位置
![图片[6]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01f6477aba1d28375f.webp)
二、代码编写
1、编写Mapper
![图片[7]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t019b8b33da2be959c0.webp)
2、编写Reduce
![图片[8]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t013ceeda98f2ae604c.webp)
3、编写主类
![图片[9]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01a174cf0347d33b4e.webp)
4、运行测试,首先我们先打一个JAR包
![图片[10]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t011ea4ce0e6c990636.webp)
![图片[11]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01ee82641ce2268602.webp)
5、我导出到本地项目中了
![图片[12]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01db04ae6ff03e3ca9.webp)
6、将包上传到我们的虚拟机中
![图片[13]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t016db44d149993a0b1.webp)
7、上传我们的测试文件,测试文件的文本结构如下,可以自己编写,中间使用空格隔开的。
hello everyone
hello hadoop
hello hadoop
hello hive
go home
come on
![图片[14]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01468315aec532d3d2.webp)
8、我们运行一下
![图片[15]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01c59f7c3196357add.webp)
![图片[16]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01f8516bd583a9d87a.webp)
9、我们查看一下浏览器,运行后的结果
![图片[17]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t017a3e55274d1b4671.webp)
10、在虚拟机查看一下文本内容
![图片[18]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01cbe67da666ec8eed.webp)
三、单词统计理解
(一)概念
1、单词统计的是统计一个文件中单词出现的次数,比如下面的数据源
![图片[19]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t0176a2e2ed491be134.webp)
2、其中,最终出现的次数结果应该是下面的显示
![图片[20]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t014e8c96ad1a7eb9e6.webp)
(二)那么在MapReduce中该如何编写代码并出现最终结果?
首先我们把文件上传到HDFS中(hdfs dfs –put …)
数据名称:data.txt,大小是size是2G
(三)进一步理解
1、红黄绿三个块表示的是数据存放的块
![图片[21]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01b2dd21168cf624ac.webp)
2、然后数据data.txt进入map阶段,会以k,v
![图片[22]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01920ea52f9c4c973f.webp)
3、那么我可以用图表示:蓝色的椭圆球表示一个map,红黄绿数据块在进入map阶段的时候,数据的形式为左边红色的k,v
![图片[23]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t0162d90b63e960afd2.webp)
4、经过map处理,比如String.split(“”),做一次处理,数据会在不同的红黄绿数据块中变为下面的KV形式
![图片[24]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t018f7145dfce87bb87.webp)
![图片[25]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t0199b5b057a06abb70.webp)
5、我们在配置Hadoop的时候或设置reduce的数量,假如有两个reduce
Map执行完的数据会放到对应的reduce中,如下图
![图片[26]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01c944c212ccc69f16.webp)
6、这个地方有一个简单的原理就是
Job.setNumReduce会设置reduce的数量
而HashPartioner类可以利用 key.hashcode % reduce的结果,将不同的map结果输入到不同的reduce中,比如a-e开头的放到一个地方,e-z开头的放到一个地方,那么
7、这样的数据结果就会变成
![图片[29]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01159a01b8926b2848.webp)
![图片[30]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01107e7215ddfff236.webp)
![图片[31]-Hadoop中单词统计案例-卡咪卡咪哈-一个博客](https://p0.ssl.img.360kuai.com/t01e085dde0c9e426ef.webp)
最终出现我们想要的结果,统计完成
四、练习
1、准备的数据:data.txt。文本内容:
hello everyone
hello hadoop
hello hadoop
hello hive
go home
come on
2、项目配置的pom文件








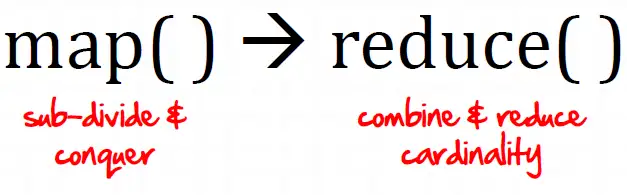









暂无评论内容