
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是spark系列的第一篇文章。
最近由于一直work from home节省了很多上下班路上的时间,加上今天的LeetCode的文章篇幅较小,所以抽出了点时间加更了一篇,和大家分享一下最近在学习的spark相关的内容。看在我这么拼的份上,求各位老爷赏个转发。。。
PS:本专题不保证每周更新,毕竟不是每周都能加更。。。
言归正传,spark鼎鼎大名,凡是搞分布式或者是大数据的应该都听说过它的大名。它是apache公司开发的一个开源集群计算框架,也就是分布式计算框架。相比于Hadoop的MapReduce,它支持更多的功能,并且运算速度也更快,如今已经成了非常主流的大数据计算框架。几乎各大公司当中都有它的身影。
spark支持像是java、scala和Python等众多语言,但是对于spark来说语言不太重要,不同的语言写出来的spark代码相差不太大。和之前的文章一样,我会以Python为主,毕竟Python对初学者比较友好(虽然我自己在工作当中使用的是scala)。
今天这篇文章从最基础的spark安装开始讲起,安装spark并不需要一个庞大的集群,实际上单机也可以。这也是我们学习的基础,这样我们就可以在本机上做各种实验了。和大多数环境不同,spark的安装要简单得多,这也是它比较友好的地方。
下载安装
进入spark官网,点击download
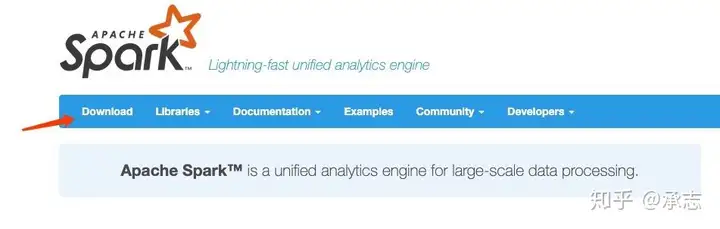
选择Pre-built for Apache Hadoop,这样我们就不用预先安装Hadoop了,相信我,安装Hadoop是一件非常痛苦的事情。。。
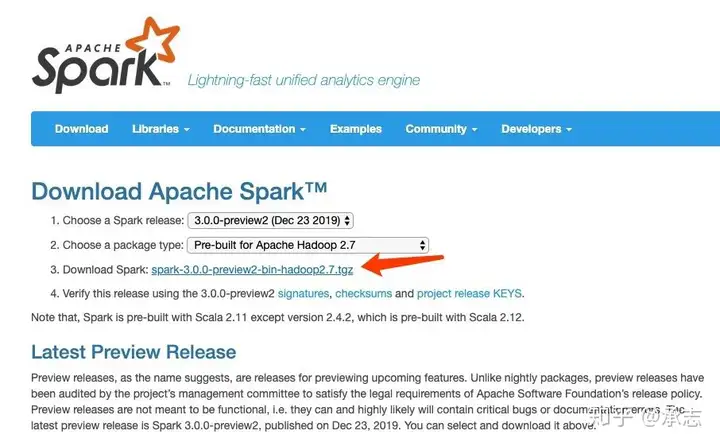
在跳转的链接当中继续点击,开始下载。
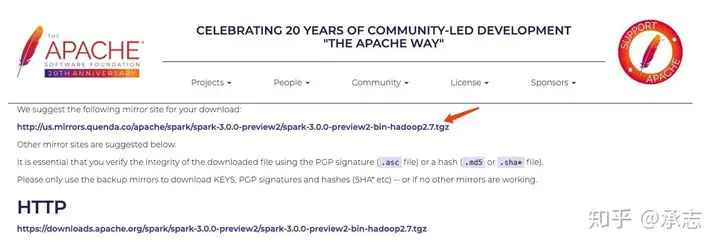
压缩包大概在230MB左右,不是特别大,很快能下好。下好了之后会得到一个tgz的压缩包。如果是Mac的话可以直接解压,如果是Windows的话可以用7z等解压工具进行解压。
也可以使用命令行进行解压:
解压完了之后记住你放的位置,当然我更建议你放在专门的位置。或者可以放在/usr/local下。
使用命令进行移动:
基本配置
放置好了之后,我们打开配置文件修改环境配置。因为我用的是zsh的终端,如果是原生的终端的话应该是.bash_profile,由于我用的是mac,如果是windows用户,请百度windows设置环境变量。。。
在末尾加上三行:
改完了之后,别忘了source ~/.zshrc激活一下。
之后我们运行一下pyspark,看到熟悉的logo就说明我们的spark已经装好了
目前为止常用的spark方式主要有两种,一种是通过Python还有一种是通过Scala。这两种都蛮常见的,所以我们可以简单了解一下。
进阶配置
下面介绍最基本的开启方法,Python的开启方法我们刚才已经介绍过了,可以直接使用pyspark命令进行唤醒。对于Scala来说也差不多,不过命令换了一下,不叫pyspark也不叫scspark,而是spark-shell。
出来的界面大同小异,只不过语言换成了Scala:
无论是pyspark还是spark-shell都只是spark提供的最基础的工具,使用体验并不好,已经不太适合现在的需求了。好在针对这个问题也有解决方案,一种比较好的解决方式是配置jupyter notebook。
jupyter notebook是非常常用的交互式编程的工具,广泛使用。我们可以在jupyter notebook当中配置Scala和Pyspark。
首先介绍Scala。
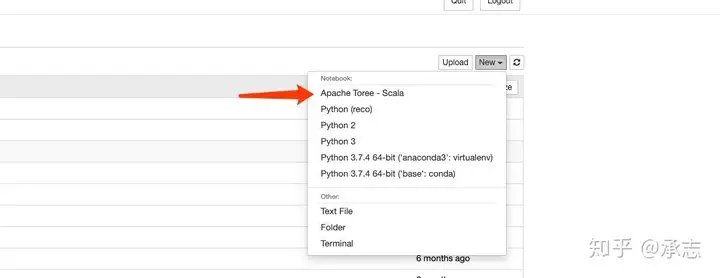
Scala的配置方法很简单,由于我们已经配置好了spark的环境变量,我们只需要安装一下jupyter下Scala内核Toree即可。安装的方式也非常简单,只需要两行命令:
运行结束之后, 我们打开点击添加,可以发现我们可以选择的内核多了一个:
pyspark的配置也很简单,我们只需要在.zshrc当中添加两个环境变量:
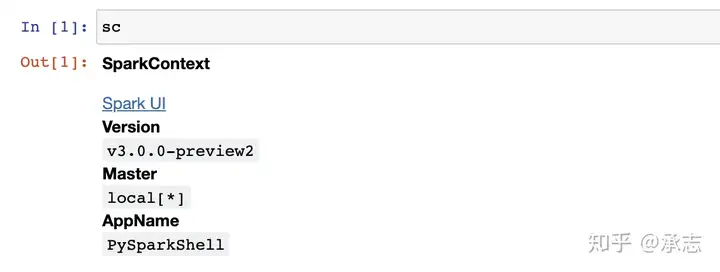
配置好了之后,我们只需要在终端输入pyspark就会自动为我们开启一个新的jupyter网页。我们选择Python3的内核新建job就可以使用pyspark了。我们执行一下sc,如果看到以下结果,就说明我们的pyspark已经可以在jupyter当中执行了。
到这里,关于spark的安装配置就介绍完了。由于我个人使用的是Mac电脑,所以一些配置方法可能对其他系统的电脑并不完全适用。但是配置的过程是大同小异的,一些具体的细节可以针对性地进行调整。
spark是当下非常流行的大数据处理引擎,使用非常广泛,所以了解和掌握spark,也是非常重要的技能。和Hadoop比起来它的安装和使用都要简便许多,希望大家都能体会到它的魅力。



















暂无评论内容