
大数据共370篇 第9页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

如何设置具有HDFS高可用性的Hadoop集群
HDFS 2.x 高可用性集群架构 在这篇博客中,我将讨论 HDFS 2.x 高可用性集群架构以及设置 HDFS 高可用性集群的过程。这是大数据课程的重要组成部分。 本博客中涵盖主题的顺序如下: HDFS HA 架...

Go语言核心36讲(Go语言进阶技术三)–学习笔记
09 | 字典的操作和约束 至今为止,我们讲过的集合类的高级数据类型都属于针对单一元素的容器。 它们或用连续存储,或用互存指针的方式收纳元素,这里的每个元素都代表了一个从属某一类型的独立...
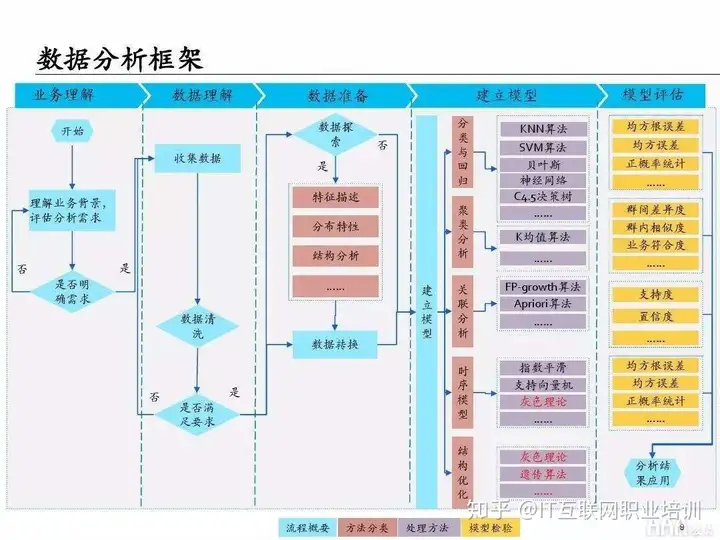
大数据分析Apache Spark的有哪些应用实例?
Apache Spark在实际应用中迅速获得发展。加州大学伯克利分校的AMPLab于2009年开发了Spark,并于2010年将其开源。从那时起,它已发展成为大数据领域最大的开源社区之一,拥有来自50多个组织的...

ByConity 如何在 Kubernetes 上无感扩缩容
原标题:ByConity 如何在 Kubernetes 上无感扩缩容 ByConity 是一个由字节跳动开源的云原生数据仓库引擎,采用存储计算分离的架构,实现了读写分离和弹性扩缩容。这款引擎支持多个关键功能特性...

代号spark国际服调中文方法,非常简单
原标题:代号spark国际服调中文方法,非常简单 有很多喜欢玩游戏的朋友最近应该都听说过代号spark国际服这款游戏,因为这款游戏的地图非常大,可以让玩家在游戏中自由探索。4月23日代号spark国...
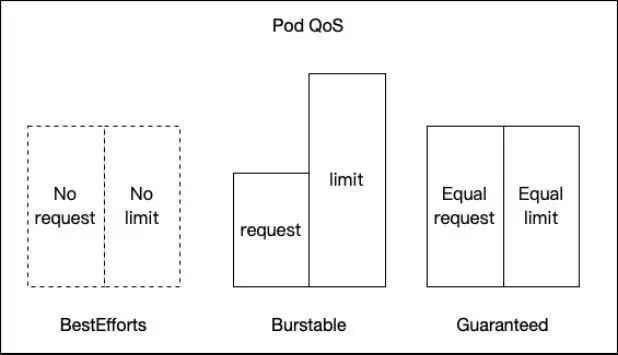
看腾讯如何提升 Kubernetes 集群利用率?
提到近两年的技术热词,“云原生”觉得是位居前列。从云计算大数据再到如今的云原生时代,一大批新技术涌现,例如当下最火热的系统部署和容器服务平台Kubernetes(K8s),K8s 甚至被不少人认...
我的面板

看一看

如何用ChatGPT设计出可控制的代码?古代最奇葩的昏君,让妃子躺在桌上与大臣共赏,从此诞生一个成语
【编者按】如何训练 ChatGPT 实现自己想要的代码与功能,秘诀就是编写更具交互性和前瞻性的设计提示,本文作者分享了如何利用 ChatGPT 设计出可控制的代码步骤。 原文链接:https://www.friendl...
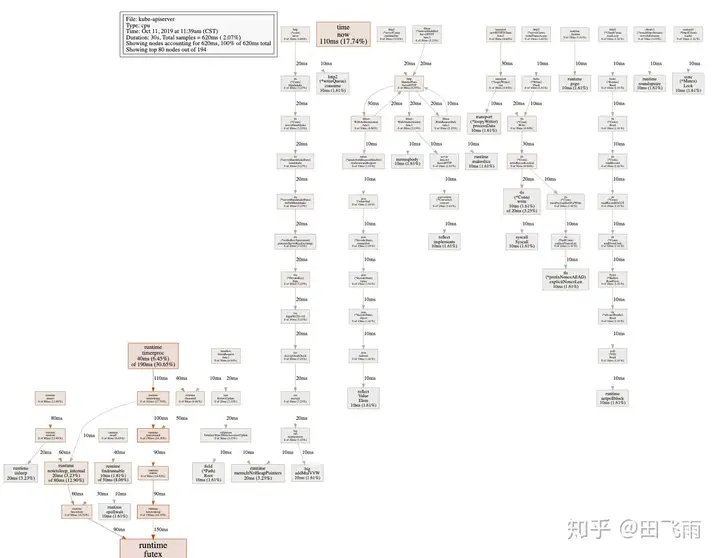
大规模场景下 kubernetes 集群的性能优化
一、etcd 优化1、etcd 采用本地 ssd 盘作为后端存储存储2、etcd 独立部署在非 k8s node 上3、etcd 快照(snap)与预写式日志(wal)分盘存储etcd 详细的优化操作可以参考上篇文章:etcd 性能测试与...
Springboot3+微服务实战12306高性能售票系统
每一个后台服务开放一个REST API,许多服务本身也采用了其它服务提供的API。比如,驾驶员管理使用了告知驾驶员一个潜在需求的通知服务。UI服务激活其它服务来更新Web页面。所有服务都是采用异步...

掌握智慧种植技术,果农不用愁,管理方便超实用
你们有没有发现,现在的很多瓜果没有以前好吃了?比如番茄,记忆中的番茄炒蛋酸甜可口,而现在的番茄不酸甜了,炒出来的菜要么是甜的要么是咸的,而且汁水少。我们记忆中的色泽鲜艳,口感优质、...

模型应用-使用Stable Diffusion UI手册
序 随着越来越多的人追上'AI绘图'这一热潮,Stable Diffusion 的受欢迎程度继续爆炸式增长。 作为模型公开且效果极佳的扩散模型Stable Diffusion是CompVis研究团队上个月(8月底)发布的。该模型...
Kubernetes系统精讲 Go语言实战K8S集群可视化高清
Kubernetes系统精讲 Go语言实战K8S集群可视化 点我必看!如何download课程 Kubernetes是目前最为流行的容器编排平台,它可以实现应用程序自动部署、升级、伸缩和管理。Go语言是Kubernetes客户端...

