
大数据共370篇 第58页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序
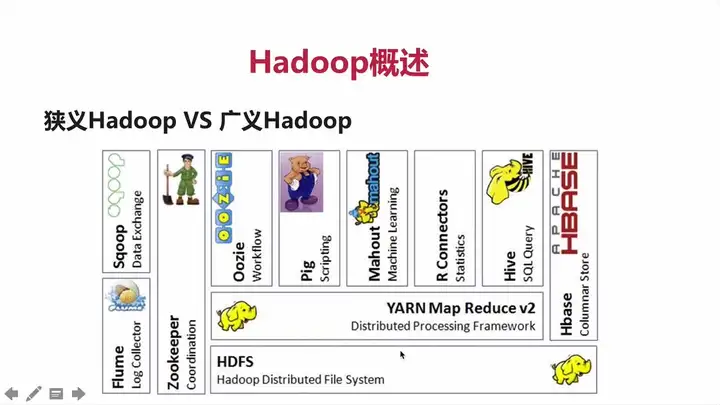
Hadoop入门教程之HDFS架构
为什么要用Hadoop? 1.源码开源 2.社区活跃,参与者很多 3.涉及到分布式存储和计算的方方面面: Flume进行数据采集 Spark/MR/Hive等进行数据处理 HDFS/HBase进行数据存储 4.已经得到企业界的验...
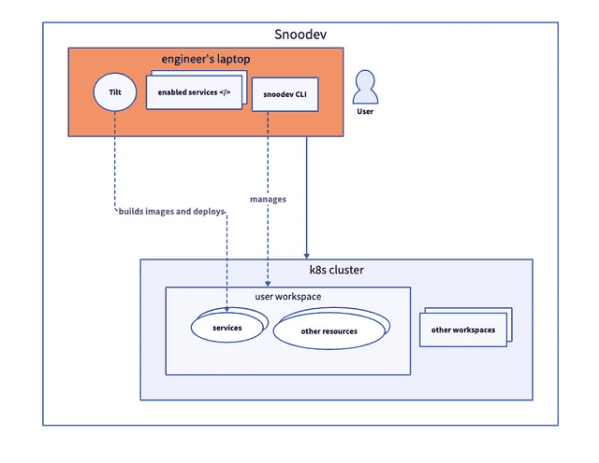
为什么大型工程团队要在 Kubernetes 上进行测试?
原标题:为什么大型工程团队要在 Kubernetes 上进行测试? 将来,开发人员应该如何处理生产应用程序呢?是应该将本地的生产环境复制到云,还是应该直接在云环境中编写和运行所有代码,或者采用...

超详细,Windows系统搭建Flink官方练习环境
如何快速的投入到Flink的学习当中,很多人在搭建环境过程中浪费了太多的时间。一套一劳永逸的本机Flink开发环境可以让我们快速的投入到Flink的学习中去,将精力用在Flink的原理,实战。这也对于...
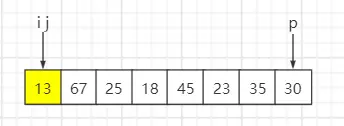
通俗易懂的快速排序算法-go语言实现
基本原理 核心思想 每次排序都会选一个基准数,小于基准数的放在左子序列,大于等于基准数的放在右子序列。 原始序列:{13, 15, 8, 54, 23} step1:随机选一个基准数15,则其左子序列{13, 8},...
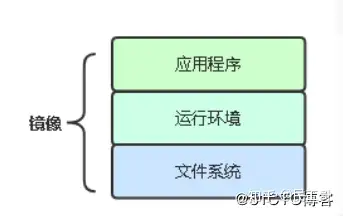
小伙!Kubernetes 部署如此简单,你看完全明白了
将项目迁移到k8s平台是怎样实现的?制作镜像控制器管理PodPod数据持久化暴露应用对外发布应用日志/监控 1、制作镜像分为三步第一基础镜像,是基于哪个操作系统,比如Centos7或者其他的第二步中间...
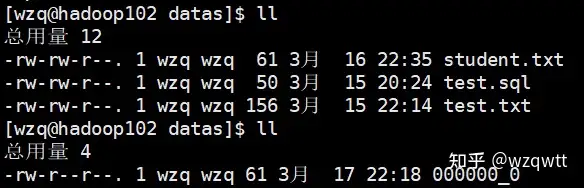
Hive数据的导入与导出
首先开启Hadoop服务,然后开启Hive服务: [wzq@hadoop102 hive-3.1.2]$ myhadoop.sh start [wzq@hadoop102 hive-3.1.2]$ hiveservices.sh start [wzq@hadoop102 hive-3.1.2]$ hive hive (defaul...
我的面板

看一看
如何创建NFT?新手指南看过来!
如何创建NFT?新手指南看过来!mp.weixin.qq.com/s/o9wFSXeo6hjR95cMS6xV_w 区块链技术为艺术的未来打开了大门,在这里,你可以放心地拥有网络空间的数字资产。NFT,不可替代的代币,增加了区...

Nvidia公布新文本转视频模型 基于Stable Diffusion开发
站长之家4月20日 消息:Nvidia公布了其基于Stable Diffusion 模型开发的文本转视频模型—— Nvidia Video LDM。Nvidia通过对现有模型的微调,大大减少了生成视频的过程和时间。 该模型增加了一个...

如何用Three.js快速实现全景图
封面图 by Thư Anh on Unsplash去年全景图在微博上很是火爆了一阵,正好我也做过一点全景相关的项目,这些天抽空写下这一篇用Three.js来实现全景图的文章,和大家一起探讨。真的是抛砖引玉,还...
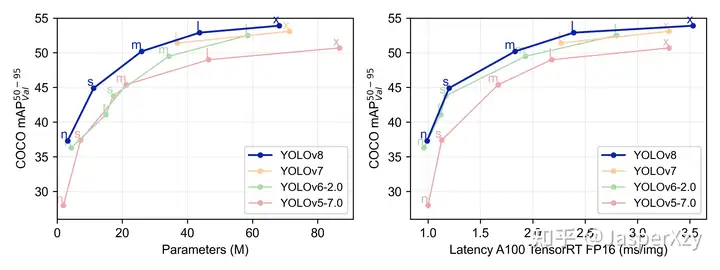
YOLOv8 预览与使用指南
摘要 YOLOv8 是最新的最先进的 YOLO 模型,可用于对象检测、图像分类和实例分割任务。YOLOv8 由 Ultralytics 开发的一个前沿的 SOTA 模型,它在以前成功的 YOLO 版本基础上,引入了新的功能和改...

今天来聊一聊最近比较热门的AI技术
随着人工智能的快速发展,像ChatGPT、文心一格和文心一言等人工智能产品的出现,正不断影响和改变我们的生活方式。这些新技术的应用,既为我们带来了更高效、更便捷的服务,同时也对传统职业领...

AI·她的关键词|AIGC绘画“她力量”
AI·她的关键词|AIGC绘画“她力量” 00:00 01:05 打开凤凰新闻客户端 提升3倍流畅度 女性没有唯一的定义,她们是立体的、广泛的,无法用定点完全表达。她们可以是明艳的玫瑰,可以是烂漫的雏菊...

