
大数据共370篇 第49页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

大数据分析技术与实战之 Spark Streaming
Spark是基于内存的大数据综合处理引擎,具有优秀的作业调度机制和快速的分布式计算能力,使其能够更加高效地进行迭代计算,因此Spark能够在一定程度上实现大数据的流式处理。 随着信息技术的迅...

ApacheFlink开发及应用指南,流式处理速度超快
ApacheFlink背景ApacheFlink行业价值如何搭建一个flink项目编写一个flink程序配置一个maven项目添加了flink的相关依赖基于flink的java案例把flink应用程序打包部署至flink平台Flink总结ApacheFl...

大数据开发 | SPARK ON YARN运行模式
原标题:大数据开发 | SPARK ON YARN运行模式 面试过程中经常被问到spark on yarn的运行模式及区别,接下来我们从多方面展开阐述。 一、YARN介绍 Yarn 的全称是 Yet Anther Resource Negotiator...

安装 Hadoop:设置单节点 Hadoop 集群
安装 Hadoop:设置单节点 Hadoop 集群 你一定对Hadoop,HDFS及其架构有一个理论概念。 但是要获得Hadoop认证,您需要良好的实践知识。我希望你会喜欢我们之前关于HDFS架构的博客,现在我将...
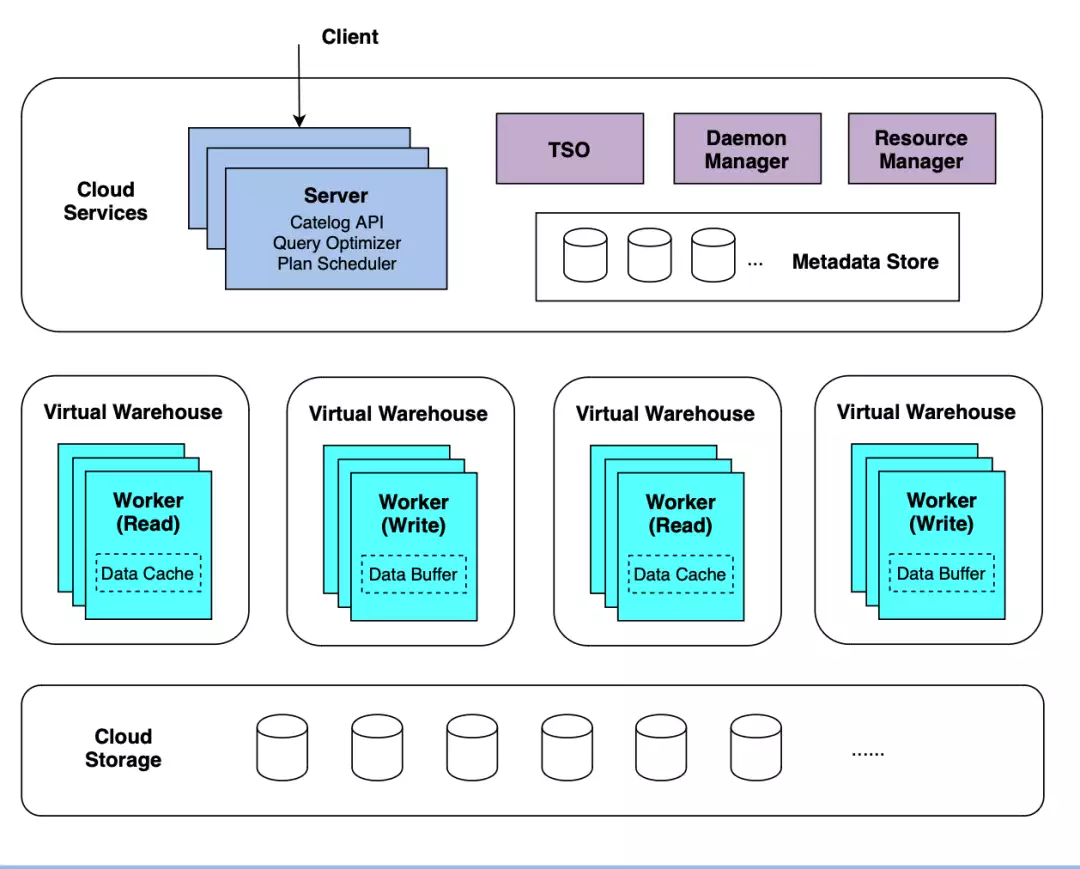
ByConity 如何在 Kubernetes 上无感扩缩容强吻、摸胸、掀裙底,这些男星究竟是真敬业,还是借戏揩油?
ByConity 是一个由字节跳动开源的云原生数据仓库引擎,采用存储计算分离的架构,实现了读写分离和弹性扩缩容。这款引擎支持多个关键功能特性,如资源隔离、无感扩缩容、高性能和数据的强一致性...

YARN资源分配,没有比这说的更清楚的了
让你彻底搞明白YARN资源分配 - 知乎 (zhihu.com)本篇要解决的问题是:Container是以什么形式运行的?是单独的JVM进程吗?YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚...
我的面板

看一看

2分钟,单视图3D生成又快又好!北大等提出全新Repaint123方法
编辑:LRS 好困 【新智元导读】将2D扩散模型的强大图像生成能力与再绘策略的纹理对齐能力结合起来,Repaint123能够在2分钟内从零开始生成具有多视角一致性和精细纹理的高质量3D内容。 将一幅图...

十年磨一剑,这家企业基于AR平台打造数字超人和智慧空间
本文转自:人民网-上海频道 在一次跨国远程装配时,国内现场工程师佩戴HiAR G200,将第一视角的现场画面通过5G网络实时推送给位于德国和奥地利的工程师,而国外工程师依托AR实时空间标注、音视...
美国西北大学芬伯格医学院基于浪潮AI服务器开发NLP辅助放射影像检查随访
北京2022年7月6日 /美通社/ -- 随着人工智能不断向行业应用渗透,多技术交叉正在给各个领域的创新带来新的想象力。在医疗健康领域,AI专家和医学专家们正在一起推动从疾病辅助诊断、辅助决策、...

Kubernetes 如何打赢容器之战?
阿里妹导读:Kubernetes 近几年很热门,在各大技术论坛上被炒的很火。它提供了强大的容器编排能 打开凤凰新闻,查看更多高清图片 阿里妹导读:Kubernetes 近几年很热门,在各大技术论坛上被炒的...
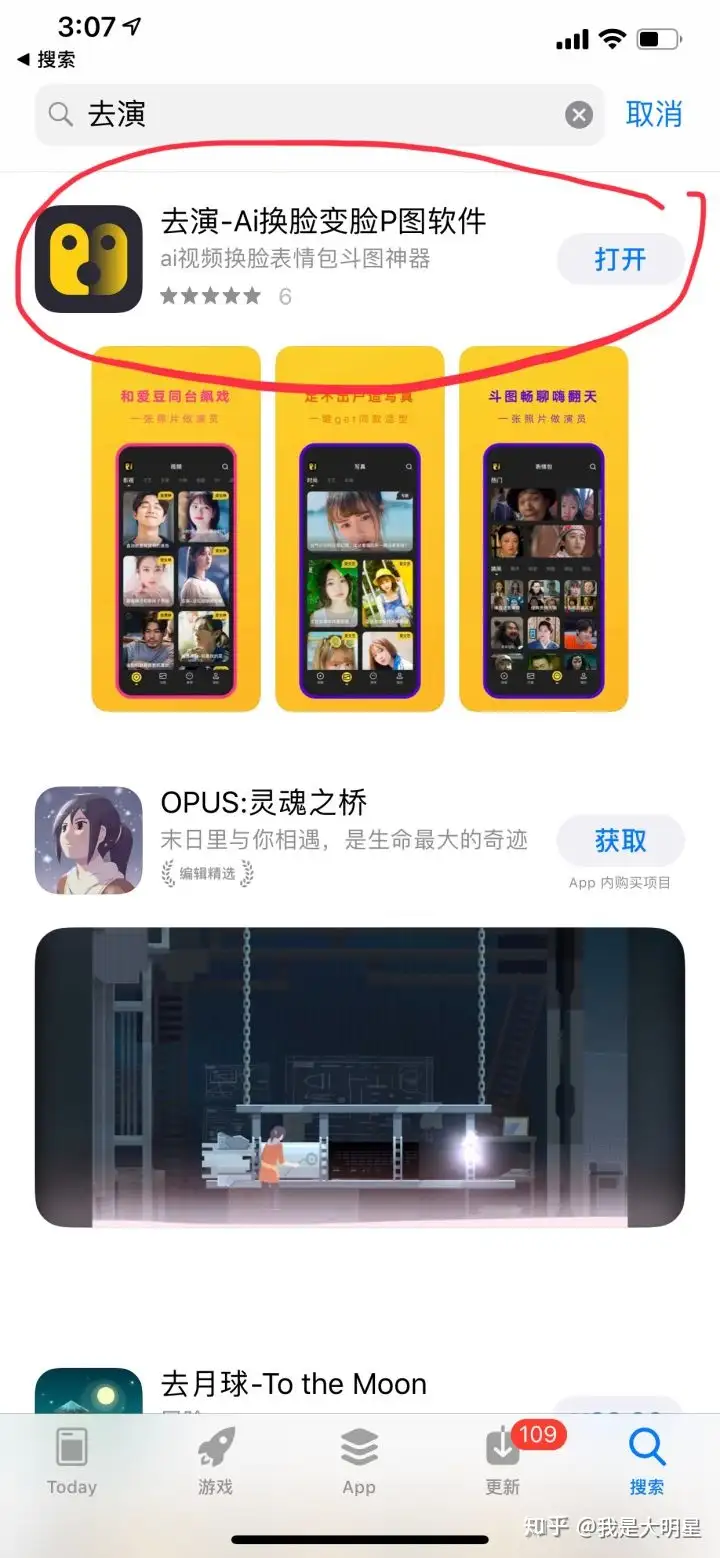
AI换脸技术用的是什么软件?
推荐一个比zao更好玩的ai换脸app——【去演】。 从去年zao的爆火,不管男女老少,都可以直接接触到AI技术的新奇体验。看似遥不可及的科学技术,原来自己操作起来也是那么简单。但是后期由于隐私...

AIGC入门教程:Stable Diffusion,万字保姆篇
AI 技术的进步为我们的工作带来了更多挑战,比如不少人可能就对新出现的 AI 绘画软件应用感到不太熟练。而在本篇文章里,作者就针对 Stable Diffusion 这款 AI 绘画软件的使用输出了这份 ' 保姆...

