
大数据共370篇 第43页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序
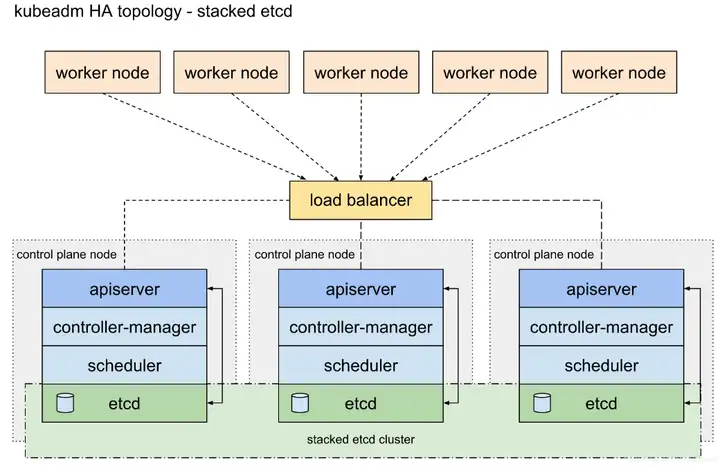
Kubernetes实战:高可用集群的搭建和部署
摘要:官方只提到了一句“使用负载均衡器将 apiserver 暴露给工作节点”,而这恰恰是部署过程中需要解决的重点问题。本文分享自华为云社区《Kubernetes 高可用集群落地二三事》,作者:zuozewei...
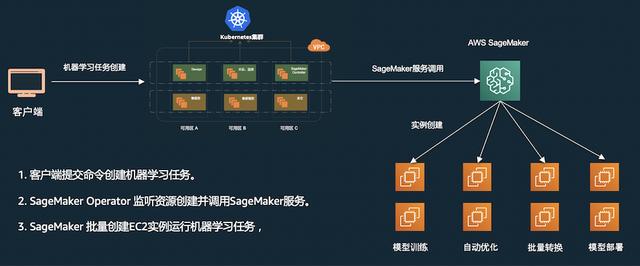
利用 SageMaker Operator 简化 Kubernetes 上的机器学习任务管理
Amazon SageMaker Operator 可以帮助数据科学家以及开发人员利用Kubernetes的接口来创建和管理SageMaker的任务,如机器学习的模型训练、超参优化、批量转换以及实时推理等。如图所示,SageMaker...

大数据分析技术与实战之 Spark Streaming
Spark是基于内存的大数据综合处理引擎,具有优秀的作业调度机制和快速的分布式计算能力,使其能够更加高效地进行迭代计算,因此Spark能够在一定程度上实现大数据的流式处理。 随着信息技术的迅...

ApacheFlink开发及应用指南,流式处理速度超快
ApacheFlink背景ApacheFlink行业价值如何搭建一个flink项目编写一个flink程序配置一个maven项目添加了flink的相关依赖基于flink的java案例把flink应用程序打包部署至flink平台Flink总结ApacheFl...

大数据开发 | SPARK ON YARN运行模式
原标题:大数据开发 | SPARK ON YARN运行模式 面试过程中经常被问到spark on yarn的运行模式及区别,接下来我们从多方面展开阐述。 一、YARN介绍 Yarn 的全称是 Yet Anther Resource Negotiator...

安装 Hadoop:设置单节点 Hadoop 集群
安装 Hadoop:设置单节点 Hadoop 集群 你一定对Hadoop,HDFS及其架构有一个理论概念。 但是要获得Hadoop认证,您需要良好的实践知识。我希望你会喜欢我们之前关于HDFS架构的博客,现在我将...
我的面板

看一看

基于神经网络算法的TeamFree会议一体机降噪实战
原标题:基于神经网络算法的TeamFree会议一体机降噪实战在线会议、在线教育、直播等线上模式改变了办公、教育等行业的传统交互模式,成为时下新兴的刚需,原来小众领域的应用,正在向更广泛的领域...

请问哪里有DeepFaceLab的详细教程?
工欲善其事必先利其器,想要玩转换脸,硬件,软件,系统必须跟上!先从准备工作说起。 硬件 换脸软件出来也好几年了,但是目前依旧对硬件依赖比较大。想要在自己电脑上跑换脸软件就必须要一张显...
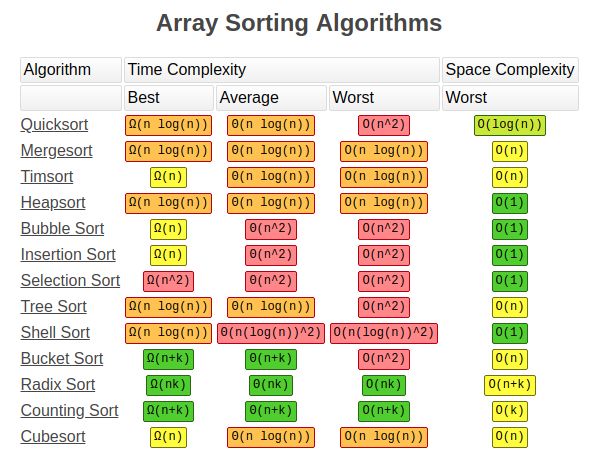
算法基础:五大排序算法Python实战教程
本文为 AI 研习社编译的技术博客,原标题 : A tour of the top 5 sortin 本文为 AI 研习社编译的技术博客,原标题 : A tour of the top 5 sorting algorithms with Python code 作者 |George ...

Kubernetes集群搭建、操作技巧和常见问题
打开凤凰新闻,查看更多高清图片 1. 集群的搭建 Kubernetes的集群是由若干个管理(master)节点和若干个工作(worker)节点组成的主机集群。这个主机集群可以通过kubectl运行docker中的镜像作为...

ChatGPT只讲这25个笑话,网友:幽默是人类最后的尊严
本文来自微信公众号:量子位 (ID:QbitAI),作者:梦晨,原文标题:《ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严》,头图来自:unsplash 如果你试过让ChatGPT...

php经典趣味算法
许多人在学习C语言的时候都写过一些有趣的算法,其实这些算法在PHP中也同样可以实现,甚至有些算法的代码比C语言中还要简洁。 1、一群猴子排成一圈,按1,2,…,n依次编号。然后从第1只开始数...

