
大数据共370篇 第4页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

SPARK+HADOOP大数据实验环境配置
最近在上大数据实验的,整理一下配置环境的过程。本文主要包括所需安装包,通用配置、hadoop配置和spark配置。一.实验环境:使用虚拟机软件:VMware Workstation Pro操作系统:Ubuntu 18.04 (mas...

K8S Liveness和Readiness的配置以及优化的一些指导
先理解下概念和核心点在Kubernetes中,Liveness和Readiness是两个关键的配置选项,用于确保应用程序在运行时的健康状态和可用性。Liveness用于检测应用程序是否在正常运行,而Readiness用于检测...

YARN资源分配,没有比这说的更清楚的了
让你彻底搞明白YARN资源分配 - 知乎 (zhihu.com)本篇要解决的问题是:Container是以什么形式运行的?是单独的JVM进程吗?YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚...

高效扩展Hadoop与Spark的数据处理工具:DataFu
Apache DataFu 是一个开源的 Apache 项目,它是一个用于大数据处理和数据分析的库。它提供了一组功能丰富的工具和函数,用于在 Apache Hadoop 和 Apache Spark 等分布式计算框架上进行数据转换...

Linux 系统上安装 Kafka 的详细步骤和命令
以下是在 Linux 系统上安装 Kafka 的详细步骤和命令。下载 Kafka首先,您需要下载 Kafka,可以从官网下载最新版本的 Kafka。假设您要下载的是 Kafka 2.9.2 版本,可以使用以下命令下载:bashwge...

超详细,Windows系统搭建Flink官方练习环境
如何快速的投入到Flink的学习当中,很多人在搭建环境过程中浪费了太多的时间。一套一劳永逸的本机Flink开发环境可以让我们快速的投入到Flink的学习中去,将精力用在Flink的原理,实战。这也对于...
我的面板

看一看
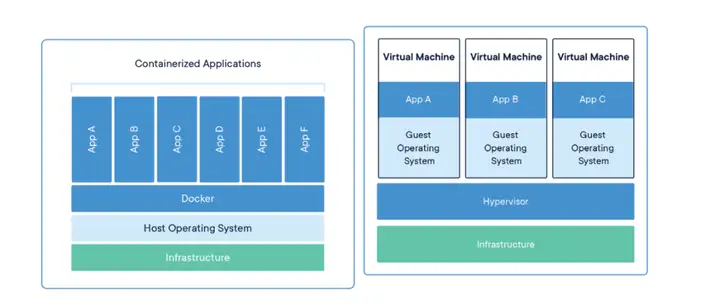
NVIDIA 大讲堂 | 什么是 KUBERNETES?
Kubernetes 是一个开源平台,用于自动进行容器编排,即容器化应用程序的部署、扩展和管理。什么是 KUBERNETES?Kubernetes 提供了一个框架,用于部署、管理、扩展和切换分布式容器,这些容器是...

机器视觉领域迎来GPT-3时刻!新模型接连炸场 图像识别门槛大幅降低
《科创板日报》4月10日讯(编辑 郑远方)短短一周不到,视觉领域接连迎来新模型“炸场”,图像识别门槛大幅降低—— 这场AI热潮中鲜见动静的Meta终于出手,推出Segment Anything工具,可准确识...
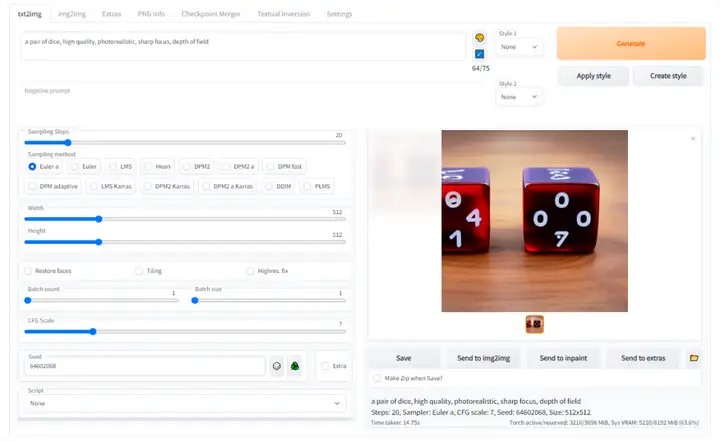
PS上的开源Stable Diffusion插件来了:一键AI脑补,即装即用
网友:「它能颠覆整个行业。」机器之心报道,编辑:蛋酱、泽南。 Stable Diffusion 是今年 AI 领域内大火的新技术,得益于 Stability AI 的开源精神,它催生了众多 AI 绘画的应用。相比传统的绘...
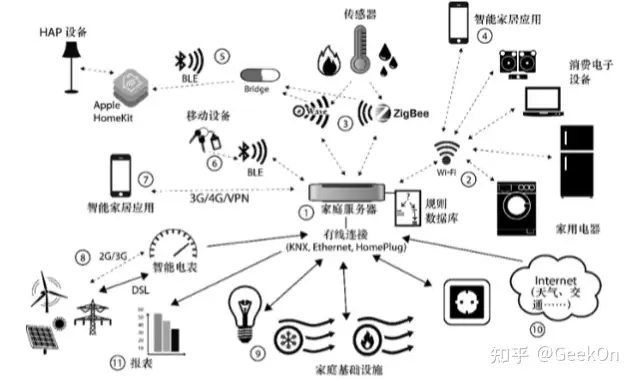
智能家居主要应用的技术有哪些?
通俗点回答吧,我想问这个问题的应该不是业内人士,更大可能是用户或者爱好者,甚至是还没入门的爱好者吧。 简单来说,智能家居主要是在传统家居技术的基础上添加了联网,以及通过网络接收和传...

如何创建高效的Prompt和ChatGPT等大语言模型AI对话
大语言模型,如OpenAI的GPT-4,是一种基于深度学习技术的自然语言处理工具,它可以理解自然语言并为用户提供有价值的回答。然而,要从大语言模型中获得高质量的回答,你需要学会如何高效地提问...
3分钟零基础,飞速上手ChatGPT,全网最全提示词案例教程
ChatGPT的强大,已经无须多言。怎么充分利用好这个强大的工具呢?掌握下面这些100个提示词(Prompt)案例教程,学会向ChatGPT高效提问,你就是ChatGPT大神!(PS:如果还没有ChatGPT账号,可以...

