
大数据共370篇 第4页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序
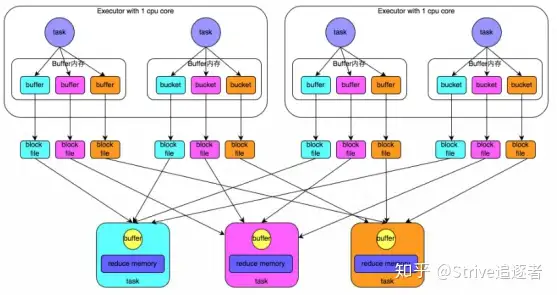
SparkShuffle及Spark SQL图解执行流程语法
1.SparkShuffle 1.1SparkShuffle概念: reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对...

spark SQL语法 与 DSL语法
[TOC] spark SQL语法 与 DSL语法 无论是hadoop、spark、flink其都具备一些共性的功能,都试图不断完善自己的功能。 包括:离线批处理api,离线批处理sql编写能力、DSL语法,实时处理能力 Hadoop...

大数据培训如何优化HiveSQL
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数...

代号spark国际服调中文方法,非常简单
原标题:代号spark国际服调中文方法,非常简单 有很多喜欢玩游戏的朋友最近应该都听说过代号spark国际服这款游戏,因为这款游戏的地图非常大,可以让玩家在游戏中自由探索。4月23日代号spark国...
阿里面试100%问到,JVM性能调优篇
JVM 调优概述性能定义吞吐量 - 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。延迟 - 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集...

Linux性能调优,看这篇就懂
做Linux性能调优,对很多人来说都蛮难的。今天小编就给大家讲讲Linux性能调优的那些事,希望能对你有帮助。 一、Linux的CPU调度 任何计算机的基本功能都十分简单,那就是计算。为了实现计算的功...
我的面板

看一看

我还没看清,他就变脸了:Deepfakes究极进化,换脸行云流水
鱼羊 栗子 发自 凹非寺量子位 报道 | 公众号 QbitAI Deepfakes要冲出天际了。 这里有一段神奇的视频 (被我裁成了动图) ,请擦亮眼睛观看。 因为讲话的人类,中途从比尔·哈德,变成了施瓦辛格:...
内存有限的情况下 Spark 如何处理 T 级别的数据?
UPDATE 1 简单起见,下述答案仅就无shuffle的单stage Spark作业做了概要解释。对于多stage任务而言,在内存的使用上还有很多其他重要问题没有覆盖。部分内容请参考评论中 @邵赛赛 给出的补充。S...
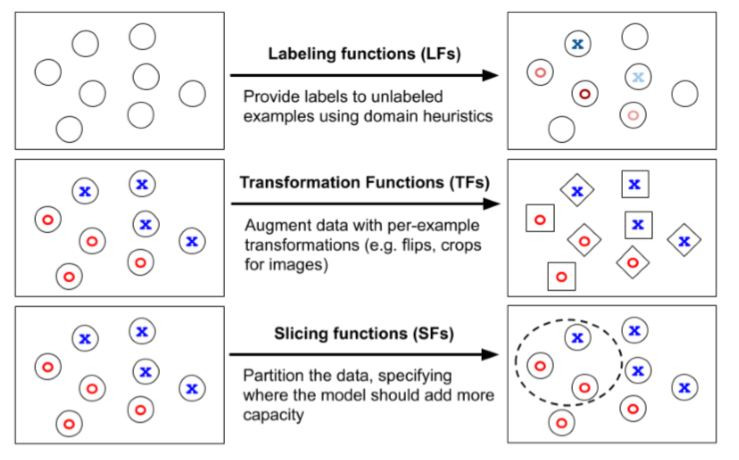
用编程创建和管理训练数据集难?三种强大的抽象方法呈上
概述 相较于在模型构架或硬件优化上所花的精力,机器学习从业者反而对训练数据更加重视。因此,程序员基于 概述 相较于在模型构架或硬件优化上所花的精力,机器学习从业者反而对训练数据更加重...
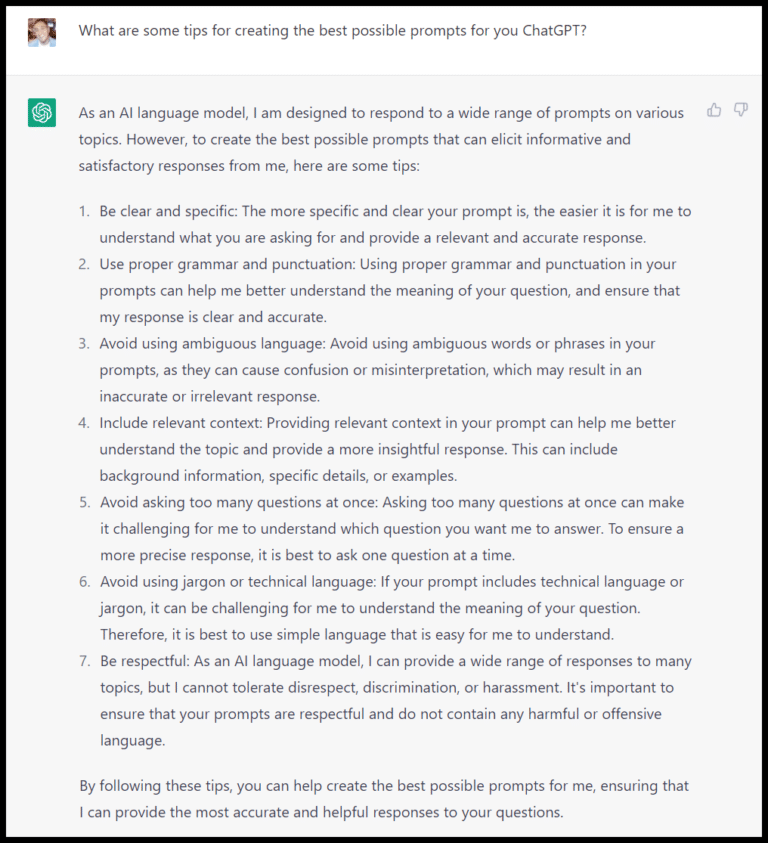
chatgpt提问prompts模板 chatgpt提示SEO指南
了解 ChatGPT 提示(和 AI 聊天/写作提示)的通用方法很有帮助,这样可以为特定应用程序创建提示。 首先你需要知道的是,ChatGPT虽然很好用,但它不会抓取网页,并且在事实、数学问题、代码等上...

智慧农业模型的应用案例
农业模型、人工智能,大数据分析等技术,贯穿于智慧农业的信息感知、信息传输、信息处理与控制全过程,是实现智慧农业的核心技术力量。所谓的农业模型,指的是农业系统要素内及要素间关系的定量...
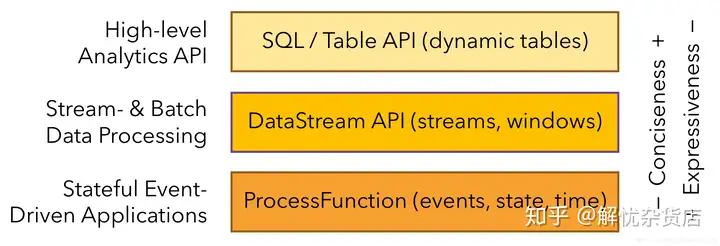
Flink小白自学指南
如何学习Flink? 前言 Flink可谓是当红炸子鸡,一线大厂都在尝试使用Flink,不少小伙伴跃跃欲试,也想学习Flink,但是却不知道该怎么学,故为大家浅薄的谈一下Flink学习之路,不当之处欢迎拍砖 ...

