
大数据共370篇 第36页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

大数据技术学习之Spark技术总结
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数...

Ubuntu物理节点上部署Kubernets集群
译者:王乐介绍这片文档介绍了如何在Ubuntu节点上部署Kubernetes,这里我们用1个主节点和3个普通节点的安装来作为范例。你可以轻松变动设置扩展到任意数量的节点。最初的想法是受到@jainvipin的...

GitLab 13.7,增加MR审阅者,部署失败时自动回滚等功能
12月22日距离平安夜还有两天,距离新年还有一周多点,又到Gitlab发版的日子了。这次发布的版本是Gitlab 13.7,虽然和日常的功能略少点,但是也包括了45项功能和改进,详细的功能请和虫虫一道学...
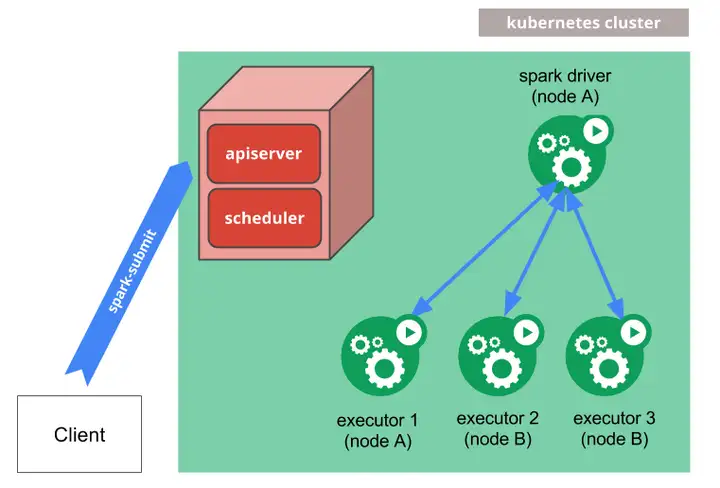
批处理任务在 Kubernetes 中的调度优化
引言 群脉通过基于虚拟机自建 Kubernetes 集群进行容器(Pod)编排,从而在保证系统稳定性的前提下大大提高了运维效率。我们内部有一条运维原则,叫做“坚持混部”,即尽量把各种不同类型的业务...
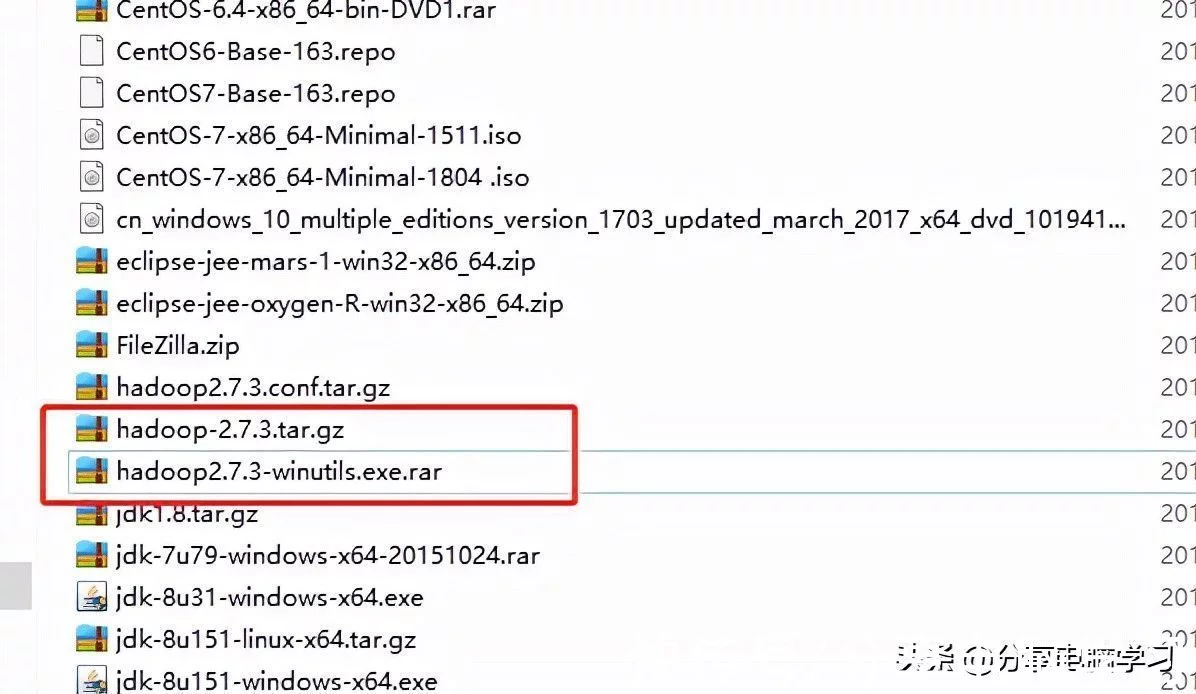
Hadoop中单词统计案例
一、搭建本地环境1、下载准备两个工具Hadoop-2.7.3.tar.gzHadoop-2.7.3-winutils.exe.rar2、将Hadoop-2.7.3-winutils.exe.rar解压后,其中的两个文件进行拷贝Hadoop.dllWintuils.exe3、将Hadoop...
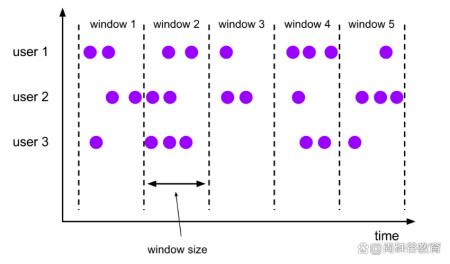
大数据培训|Flink各种窗口区别
Window是处理无限流的核心。Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。Flink提供了非常完美的窗口机制,这是Flink最大的亮...
我的面板

看一看
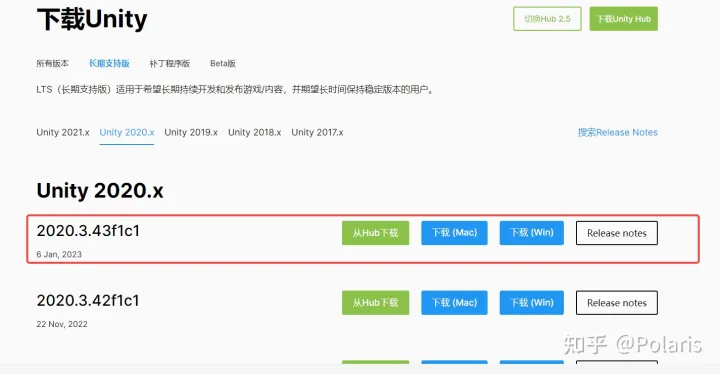
Unity做VR全平台游戏开发(二)——Unity开发环境安装
一、安装Unity 目前推荐安装Unity2020的LTS版本,即Unity2020.3.x版本 尝试过Unity2021的LTS版本,发现几乎每次打包的时候会触发重新构建Shader变体,导致打包很慢,所以放弃了,不知道目前最新...

加特技只需一句话or一张图,Stable Diffusion的公司把AIGC玩出了新花样
编辑:蛋酱 从文本生成图像,再到给视频加特效,下一个 AIGC 爆发点要出现了吗? 相信很多人已经领会过生成式 AI 技术的魅力,特别是在经历了 2022 年的 AIGC 爆发之后。以 Stable Diffusion 为...
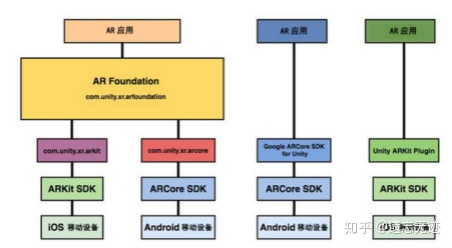
unity通过ARFoundation开发苹果AR项目(一)
想必大家在想开发苹果AR项目之前都有了解过ARKit这个工具包吧,这是unity资源商店里的一个包,但是近来这个包下架了,从资源商店搜不到了,想要的话只能去网页上搜。我在开发之前也是这样,苦苦...

AI大模型团队Colossal-AI破局创新,火热招募中!
公司简介 潞晨科技致力于解放 AI 生产力,通过高效多维并行、异构内存管理、大规模优化库、自适应任务调度等自研技术,打造面向大模型时代的通用深度学习系统 Colossal-AI ,高效促进 AI 大模型...
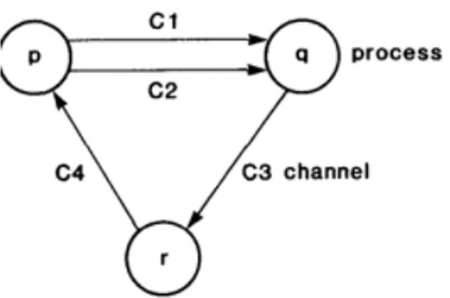
Flink端到端的一致性
- source端(kafka consumer) 偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性。 -内部(checkpoint 机制) 基于 Chandy-Lamport 算法的...

工业互联网技术加持,制造业正加速数字化转型
制造业数字化转型即传统制造业通过将生产、管理、销售各环节都与云计算、互联网、大数据相结合,促进企业研发设计、生产加工、经营管理、销售服务等业务数字化转型。 不同于其它行业,制造业的...

