
大数据共370篇 第33页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

大数据技术学习之Spark技术总结
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数...

Ubuntu物理节点上部署Kubernets集群
译者:王乐介绍这片文档介绍了如何在Ubuntu节点上部署Kubernetes,这里我们用1个主节点和3个普通节点的安装来作为范例。你可以轻松变动设置扩展到任意数量的节点。最初的想法是受到@jainvipin的...

GitLab 13.7,增加MR审阅者,部署失败时自动回滚等功能
12月22日距离平安夜还有两天,距离新年还有一周多点,又到Gitlab发版的日子了。这次发布的版本是Gitlab 13.7,虽然和日常的功能略少点,但是也包括了45项功能和改进,详细的功能请和虫虫一道学...
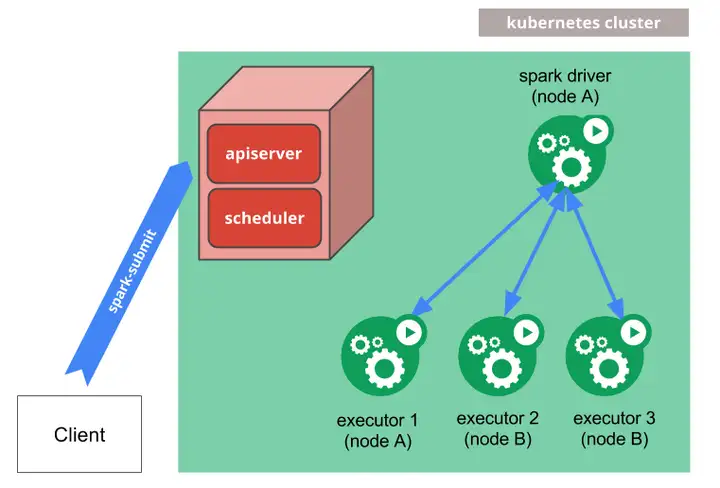
批处理任务在 Kubernetes 中的调度优化
引言 群脉通过基于虚拟机自建 Kubernetes 集群进行容器(Pod)编排,从而在保证系统稳定性的前提下大大提高了运维效率。我们内部有一条运维原则,叫做“坚持混部”,即尽量把各种不同类型的业务...
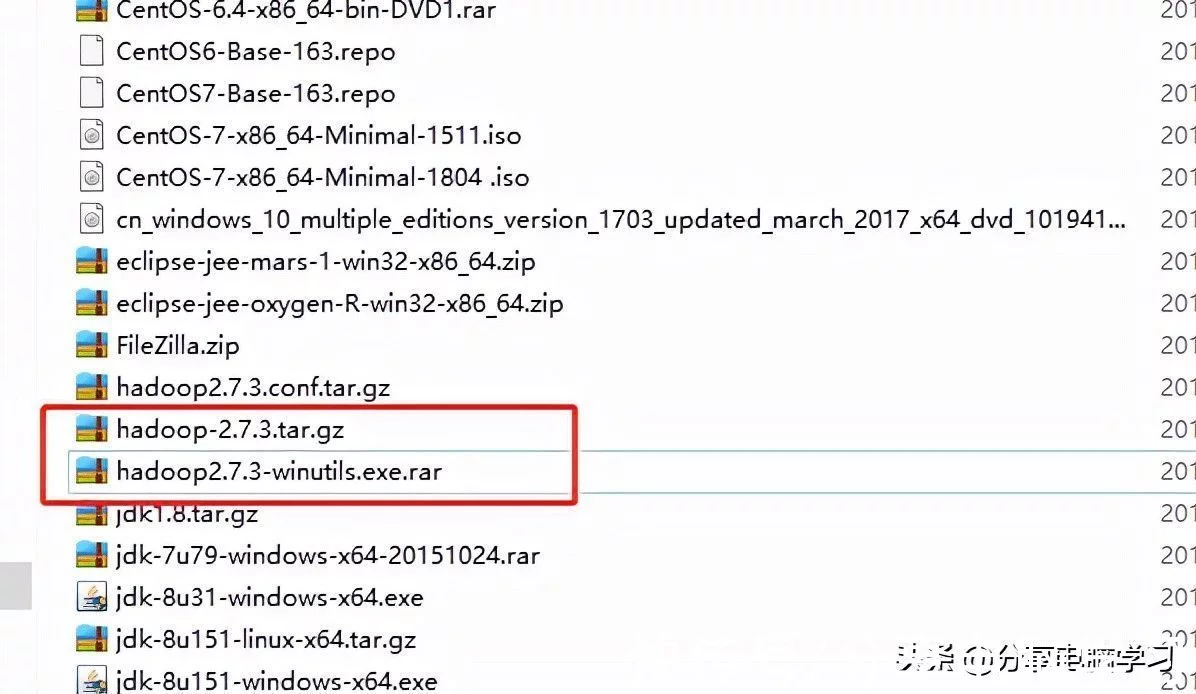
Hadoop中单词统计案例
一、搭建本地环境1、下载准备两个工具Hadoop-2.7.3.tar.gzHadoop-2.7.3-winutils.exe.rar2、将Hadoop-2.7.3-winutils.exe.rar解压后,其中的两个文件进行拷贝Hadoop.dllWintuils.exe3、将Hadoop...
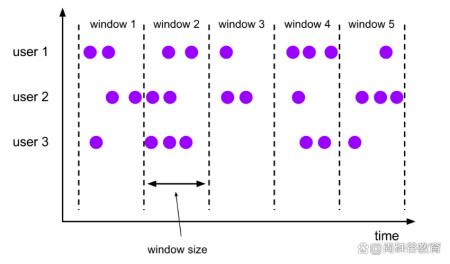
大数据培训|Flink各种窗口区别
Window是处理无限流的核心。Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。Flink提供了非常完美的窗口机制,这是Flink最大的亮...
我的面板

看一看

three.js介绍(three.js的作用)Three.js的学习资料和学习计划,统统安排上,
前言 各位同学好,我是一拳,一个兴趣使然的前端开发工程师。 我相信很多前端开发者都曾有过开发一个炫酷的3D页面的想法,当下元宇宙概念盛行,各位同学炫技的DNA是不是都蠢蠢欲动了。 我们要做...
解密 Golang 哈希算法:深入了解 MD5、SHA-1 和 SHA-256
哈希算法是计算机科学领域中一种重要的技术,它将任意长度的输入数据映射为固定长度的哈希值。在本篇文章中,我们将深入探讨 Golang 中的哈希算法,从多个方面介绍其详细内容。我们将探讨哈希算...
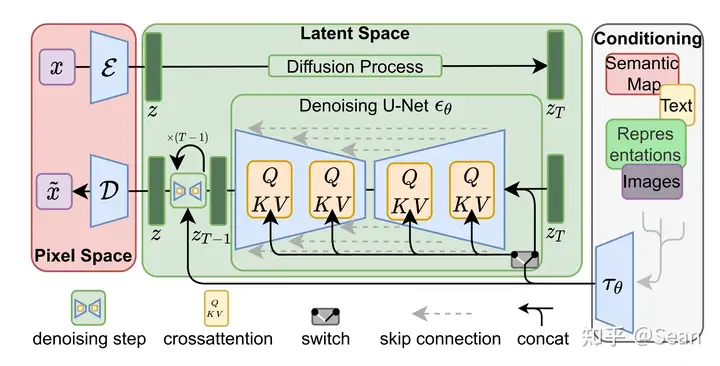
Stable Diffusion原理解读
引言 最近大火的AI作画吸引了很多人的目光,AI作画近期取得如此巨大进展的原因个人认为有很大的功劳归属于Stable Diffusion的开源。Stable diffusion是一个基于Latent Diffusion Models(潜在扩...
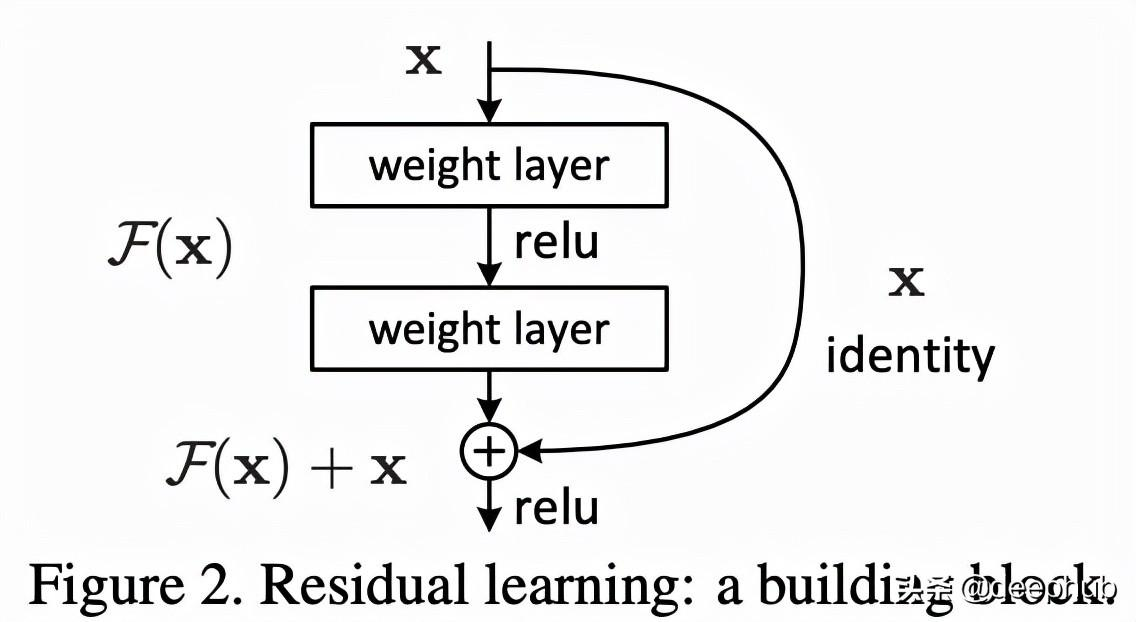
论文解释:Vision Transformers和CNN看到的特征是相同的吗?
近年来,Vision Transformer (ViT) 势头强劲。 本文将解释论文《Do Vision Transformers See Like Convolutional Neural Networks?》 (Raghu et al., 2021) 由 Google Research 和 Google Brain...

如何创建高效的Prompt和ChatGPT等大语言模型AI对话
大语言模型,如OpenAI的GPT-4,是一种基于深度学习技术的自然语言处理工具,它可以理解自然语言并为用户提供有价值的回答。然而,要从大语言模型中获得高质量的回答,你需要学会如何高效地提问...
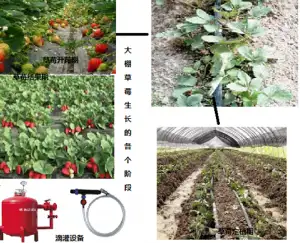
智慧农业:水肥一体化技术在大棚草莓种植中的应用
智慧农业:水肥一体化技术在大棚草莓种植中的应用 水肥一体化技术是将灌溉与施肥融为一体的农业新技术。水肥一体化是借助压力系统(或地形自然落差),将可溶性固体或液体肥料,按土壤养分含量...

