
大数据共370篇 第27页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

一套 SQL 搞定数据仓库?Flink有了新尝试
打开凤凰新闻,查看更多高清图片 阿里妹导读: 数据仓库是公司数据发展到一定规模后必然需要提供的一种基础服务,也是“数据智能”建设的基础环节。迅速获取数据反馈不仅有利于改善产品及用户体...
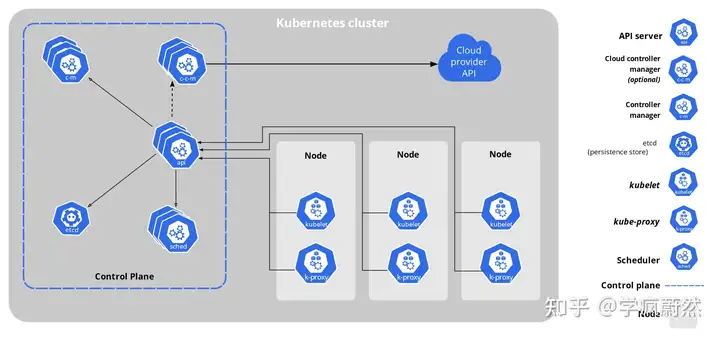
Kubernetes核心架构与高可用集群详解(含100%部署成功的方案)
Kubernetes简介 Kubernetes是Google开源的一个容器编排引擎,一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,采用声明式配置[1],支持自动化部署、大规模可伸缩、应用容器化...

上新前夕,我们跟Flink中文社区发起人聊了聊,拿到一波官方剧透
大数据文摘出品 作者:魏子敏、笪洁琼 Flink框架上!新!啦! 作为备受瞩目的新一代开源大数据计算引擎,Flink项目无疑已成为 Apache 基金会和 GitHub 最为活跃的项目之一。 自 2014 年正式开源...
手把手教你在本机配置spark
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark系列的第一篇文章。 最近由于一直work from home节省了很多上下班路上的时间,加上今天的LeetCode的文章篇幅较小,所以抽出了...

Spark性能优化总结(建议收藏)
近期优化了一个spark流量统计的程序,此程序跑5分钟小数据量日志不到5分钟,但相同的程序跑一天大数据量日志各种失败。经优化,使用160 vcores + 480G memory,一天的日志可在2.5小时内跑完,下...

Hadoop环境配置(一):Pseudo-Distributed模式
前言寒假花了很多时间在基于Giraph的PageRank这个实验上面,最终实现的效果是在服务器上的分布式环境中使用Giraph这个框架运行PageRank算法。这个系列的文章主要是把在配置Hadoop的过程中所有踩...
我的面板

看一看

web和js的区别(three.js的作用)WebVR如此近 – three.js的WebVR示例程序解析,
关于WebVR 最近VR的发展十分吸引人们的眼球,很多同学应该也心痒痒的想体验VR设备,然而现在的专业硬件价格还比较高,入手一个估计就要吃土了。但是,对于我们前端开发者来说,我们不仅可以简单...

PHP简单实现“相关文章推荐”功能的方法
摘要:通常在做内容网站的时候,需要在每一篇文章中出现与该文章相关的文章列表。对于大多数人来说,使用的方法通常是:建立一个关键词列表,判断每篇文章包含有那些关键词,最后根据关键词找出与某...

超高质量图解Stable Diffusion,看完彻底搞懂“图像生成”原理
编辑:LRS 【新智元导读】小白都能看懂的Stable Diffusion原理! 还记得火爆全网的图解Transformer吗?最近这位大佬博主Jay Alammar在博客上对大火的Stable Diffusion模型也撰写了一篇图解,让...

干货!实例讲解如何打造全屋智能–水哥智能家居案例(十六)
序:智能家居最适合怎样的人群? 很多人会回答说是这个是最新潮的科技,当然是年轻人的最爱。 年轻人喜欢折腾,喜欢时尚、新潮的科技产品,因此才会喜欢“玩”智能家居。 智能家居是爱玩人的“...

什么是物联网开发?物联网开发关键技术有哪些?
物联网开发是指在实现物联网(IoT)应用场景时所需要的技术开发。物联网是指通过互联网将一切物品互相连接起来的网络。物联网开发涵盖了物联网硬件开发、传输协议开发、数据存储和处理、应用开...

YouTube视频推荐算法:5个非常有意思的细节
YouTube会在新视频中分享有关其搜索和推荐算法工作原理的更多详细信息,该视频将帮助公司回答用户的问题。据悉,YouTube小组在本月初发布了类似的视频,尽管其最新视频回答了一系列全新问题。有...

