
大数据共370篇 第23页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

flink教程-详解flink 1.11中的新部署模式-Application模式
背景session模式per job模式per job模式的问题引入application模式通过程序提交任务Application模式源码解析入口执行具体的操作runApplication方法构造ClusterDescriptorDeploy Application Clu...
T-thinker|继MapReduce,Apache Spark之后的下一代大数据并行编程框架
机器之心专栏 严达 (Daniel Yan)| yanda@uab.edu 计算机科学系助理教授 | 美国阿拉巴马大学伯明翰分校 [欢迎随时跳过文字看最后的讲座视频直接了解 T-thinker]。 什么?是不是又是一个关于设...

大数据培训如何优化HiveSQL
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数...

使用 Kubespray 安装 Kubernetes
此快速入门有助于使用 Kubespray 安装在 GCE、Azure、OpenStack、AWS、vSphere、Equinix Metal(曾用名 Packet)、Oracle Cloud Infrastructure(实验性)或 Baremetal 上托管的 Kubernetes ...
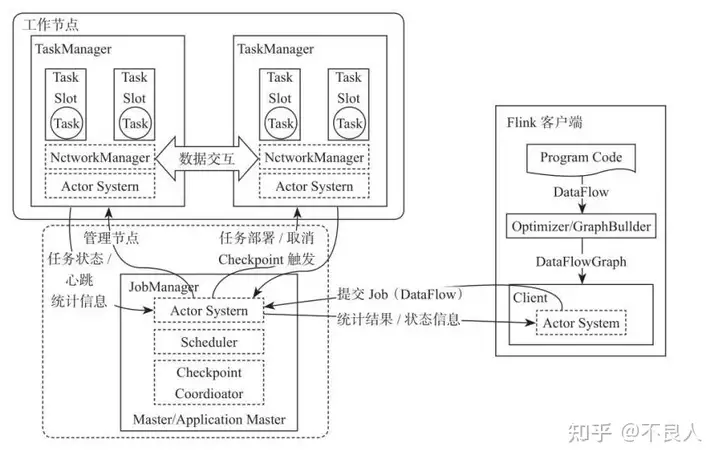
第三章 Flink基本架构及集群部署
Flink的安装和部署主要分为本地(单机)模式和集群模式,其中本地模式只需直接解压就可以使用,不用修改任何参数,一般在做一些简单测试的时候使用。本地模式在我们的课程里面不再赘述。集群模...

如何设置具有HDFS高可用性的Hadoop集群
HDFS 2.x 高可用性集群架构 在这篇博客中,我将讨论 HDFS 2.x 高可用性集群架构以及设置 HDFS 高可用性集群的过程。这是大数据课程的重要组成部分。 本博客中涵盖主题的顺序如下: HDFS HA 架...
我的面板

看一看
图解Python算法
普通程序员,不学算法,也可以成为大神吗? 对不起,这个,绝对不可以。 可是算法好难啊~~看两页书就想 普通程序员,不学算法,也可以成为大神吗? 对不起,这个,绝对不可以。 可是算法好难啊~...
Rust函数式编程全解析
闭包Rust的闭包是匿名函数,您可以将其保存在变量中或作为参数传递给其他函数。您可以在一个地方创建闭包,然后调用该闭包以在不同的上下文中对其进行评估。与函数不同,闭包可以从定义它们的作...

上海机器人研究所机器人及智能制造产业中心揭牌成立。
2月9日,位于嘉定南翔的上海机器人研究所机器人及智能制造产业中心揭牌成立。 机器人产业基地内部效果图据悉,负责该产业基地运营的新因诺维机器人工程技术研究有限公司于2022年12月入驻...

女神《吉泽明步》!引退出自传爆
「吉沢明歩(吉泽明步)」还是没办法幸免,再度曝光没有马S克的片段~目前只市面上只有8分钟的版本,期待有更完整版的释出,作品出处是她2016年在M推出的作品,有传闻是由于某种原因才泄漏出去的:...

AI绘画:革新还是“狠活”?那个高考故意考0分,写8000字抨击高考制度的蒋多多,现在怎样?
借助AI绘画软件,用户可以把牛肉面的照片拟人化。 受访者供图 输入一组关键词或照片,不出半分钟,就能获得一组由AI创作的画作……最近,一种名为“AI绘画”的技术引发公众关注。 AI绘画即人工...

浏览器中的三维空间「Three.js场景搭建」
在第一章《Three.js初体验》 中,大致介绍了在网页中渲染三维场景的简要流程。距离上一章已经过去了两周,如果你充满好奇心,并且有足够的执行力的话,相信你已经能读懂简单的JavaScript和HTML...

