
大数据共370篇 第11页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

Kubernetes实用技巧汇总
编者按: 生产环境部署k8s后,免不了要天天和k8s命令行打交道,所以要掌握一些小技巧常识,提升咱们使用K8s的工作效率,下面就由我为大家介绍,共同学习。 1、kubernetes 命令补全 首先就得说说...

QCon高分演讲:火山引擎容器技术在边缘计算场景下的应用实践与探索
原标题:QCon高分演讲:火山引擎容器技术在边缘计算场景下的应用实践与探索 2023-06-07 17:02:00 作者:宋均益 近日,火山引擎边缘云原生团队的同学在QCon全球软件开发大会上分享了火山引擎容器...

了解 Kubernetes 的 limits 和 requests
在 Kubernetes 中, 如何合理的设置容器资源请求和限制,对于优化应用程序和 k8s 集群性能至关重要。 Namespace quotas(名称空间配额) Kubernetes 允许管理人员对特定的命令空间(namespace)...

ApacheFlink开发及应用指南,流式处理速度超快
ApacheFlink背景ApacheFlink行业价值如何搭建一个flink项目编写一个flink程序配置一个maven项目添加了flink的相关依赖基于flink的java案例把flink应用程序打包部署至flink平台Flink总结ApacheFl...
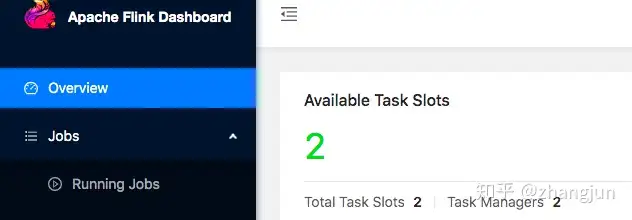
flink实战教程-集群的部署
MiniClusterStandaloneyarnyarn sessionyarn per jobapplication模式k8s其他 MiniCluster 这种模式我们一般是在用IDE调试程序的时候用到,当我们在本地用IDE开发程序的时候,执行main方法,flink...
MapReduce和Spark的区别是什么?
首先大数据涉及两个方面:分布式存储系统和分布式计算框架。前者的理论基础是GFS。后者的理论基础为MapReduce。MapReduce框架有两个步骤(MapReduce 框架其实包含5 个步骤:Map、Sort、Combin...
我的面板

看一看
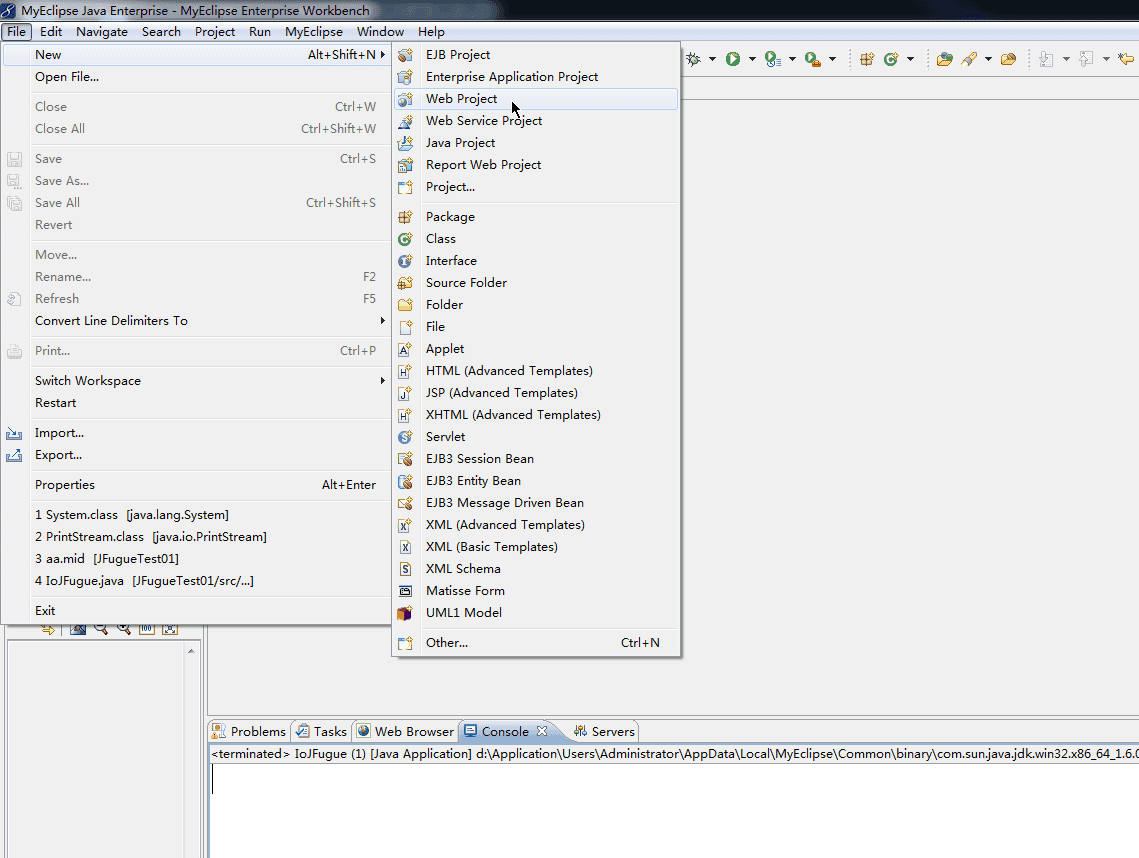
Unity3D与Java后台TomCat服务器传递数据和文件(1)建立Java服务器
文章创建与2016-03-26 作者 Aries.H 原文链接:https://blog.csdn.net/Aries_H/article/details/50986390 我用到的工具有: MyEclipse TomCat7 Unity3D 5.1.0f3 好了,闲话就说道这,直接进入正...

你真的会用提示词吗?stable diffusion提示词语法详解
提示词,即prompt、tag,也被戏称为咒语,分为正向提示词和反向提示词。 首先我们来看一下一些常用提示词写法,如下图。 我们可以发现这些提示词里面,不仅仅是英语单词的简单罗列,还会有括号...
通过Three.js,宜享花带你走进3D的世界
随着人们对用户体验越来越重视,Web开发已经不满足于2D效果的实现,而把目标放到了更加炫酷的3D效果上。Three.js是用于实现web端3D效果的JS库,它的出现让3D应用开发更简单,宜享花将通过Three....
![ChatGPT核心原理及模型讲解[科普向无公式]-卡咪卡咪哈-一个博客](https://pic4.zhimg.com/80/v2-65b7578f2ceffb00fb59b6e7ef7e714b_720w.webp)
ChatGPT核心原理及模型讲解[科普向无公式]
0️⃣.ChatGPT的核心原理理解可能确实需要一定的计算机科学和高等数学方面的积累(以及英文原著论文的研读能力),但作为对AI领域感兴趣的【非技术/学术】方面的“普通人”,以“科普门槛”进行...

AI分割一切!智源提出通用分割模型SegGPT,「一通百通」的那种
允中 发自 凹非寺 量子位 | 公众号 QbitAI 视觉领域的GPT-3时刻,真的要来了? Meta分割一切的SAM(SegmentAnything Model)刚炸完场,几乎同时,国内的智源研究院视觉团队也提出了通用分割模型...
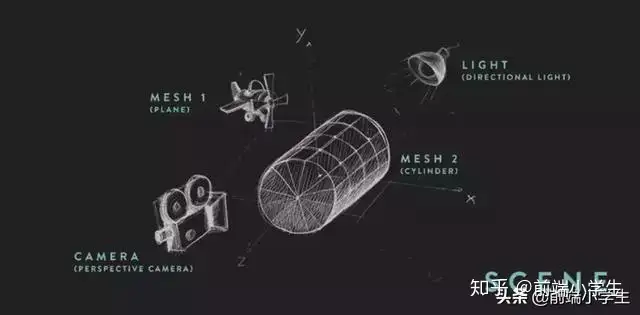
一步步带你实现web全景看房——three.js
canvas画2d相信大家都很熟悉了,但3d世界更加炫酷。我们直接从three.js入手。下面我们从0开始来摸索一下3d世界1. 基本概念 在THREEjs中,渲染一个3d世界的必要因素是场景(scene)、相机(camer...

