
大数据共370篇 第11页
大数据,离线计算,实时计算,流处理引擎,数仓技术
排序

spark—实践之DataSet实战企业人员管理系统应用案例
此案例参考书籍《Spark大数据商业实战三部曲》,特做学习笔记,巩固学习过程。案例预览:给每位员工的年龄增加100给特定的员工年龄增加70,其他增加30对人员信息中的重复数据进行去重按年龄进行...

spark处理大数据有什么优势(大数据 spark架构)大数据入门:Spark Streaming实际应用
作为Spark负责流计算的核心组件,Spark Streaming是整个Spark学习流程当中非常重要的一块。对于Spark Streaming,作为Spark流计算的实际承载组件,我们也需要更全面的掌握。今天的大数据入门分...

代码+案例详解:使用Spark处理大数据最全指南
全文共17984字,预计学习时长30分钟或更长如今,有不少关于Spark的相关介绍,但很少有人从数据科学家的角度来解释该计算机引擎。因此,本文将试着介绍并详细阐述——如何运行Spark?一切是如何...

spark大数据教程(spark大数据分析源码解析)《Spark大数据分析实战》笔记
写在前面:此书很棒,但需要一定的编程功底,此外强烈建议买书,因为很多架构图、算子列表,我也不会摘抄下来。 第一章 简介 1.Spark执行的特点 Hadoop中包含计算框架MapReduce和分布式文件系统...

不使用 Kubernetes 发行版的5个理由
导读:Kubernetes不是 Linux,请给原生Kubernetes一个机会。 目前有不少公司基于 Kubernetes 封装了自己的商用 Kubernetes 发行版,丰富了开发生态,也提供给开发者更多选择。 最近有人提出,选...

如何在 Kubernetes Pod 和您的机器之间复制文件
在 Kubernetes Pod 中运行的容器是不需要手动交互的独立计算单元。有时您可能需要将文件复制到 Pod 的文件系统或从 Pod 的文件系统复制文件,这可能是因为您正在调试问题并希望存档存储在容器中...
我的面板

看一看

AI绘画常用提示词
风格提示词 gothic哥特式 Ukiyoe日本浮世绘风格 Traditional Chinese painting中国国画 coil painting油画 realism现实主义 film noir黑暗风格 water colour painting水彩画 Romanticism浪漫主...

拒绝白嫖!Stable Diffusion新版:画师可自主选择作品是否加入训练集
衡宇 发自 凹非寺量子位 | 公众号 QbitAI不希望自己作品被Stable Diffusion“白嫖”的画家们,可以松口气了! Stable Diffusion 3.0版本将会提供一个选项: 艺术家们可以选择将自己的画作纳入St...
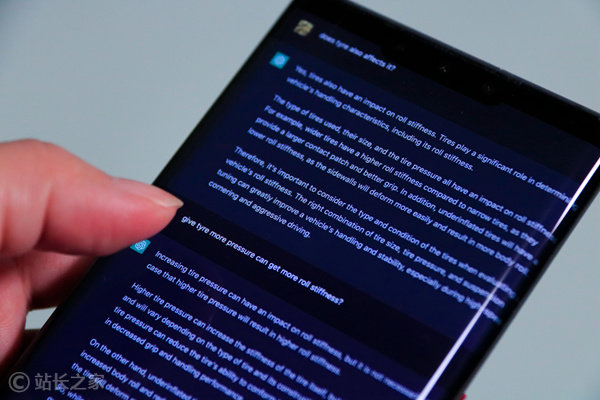
chatgpt提问prompts模板分享 SEO专员不可错过的5个ChatGPT 提示
站长之家 3月7日 消息:随着人工智能技术的发展,想要成为SEO内容大师,必须要掌握ChatGPT的使用技巧才行。今天,小编整理了一份ChatGPT 提示列表,希望对大家有所帮助。 从关键字研究到内容创建...
黑箱优化:大规模语言模型的一种落地方式
年前最后一个工作终于完成了初稿,借此空闲写一下最近关于大规模预训练语言模型落地的一些思考,也顺便分享一下刚刚发布的Black-Box Tuning: https://arxiv.org/abs/2201.03514Update: Black-Bo...

JS爬虫实战:点击网页抓取数据,
在当今信息化时代,数据是一种宝贵的资源。然而,要想获取大量的数据并不是一件容易的事情。如果人工采集,不仅费时费力,而且效率低下;而如果使用JS爬虫技术,可以轻松地从网页中获取所需数据...

识农受邀参与2019广州国际智慧农业技术及温室设备展,用AI为农业赋能!
2019年9月5-7日,2019广州国际智慧农业技术及温室设备展在广州琶洲保利世贸博览馆盛大举办,深圳市识农智能科技有限公司受邀参展,并在同期举办的《中国(广州)智慧农业技术应用论坛》上发表演...

